IMAMURA, Genichi
-
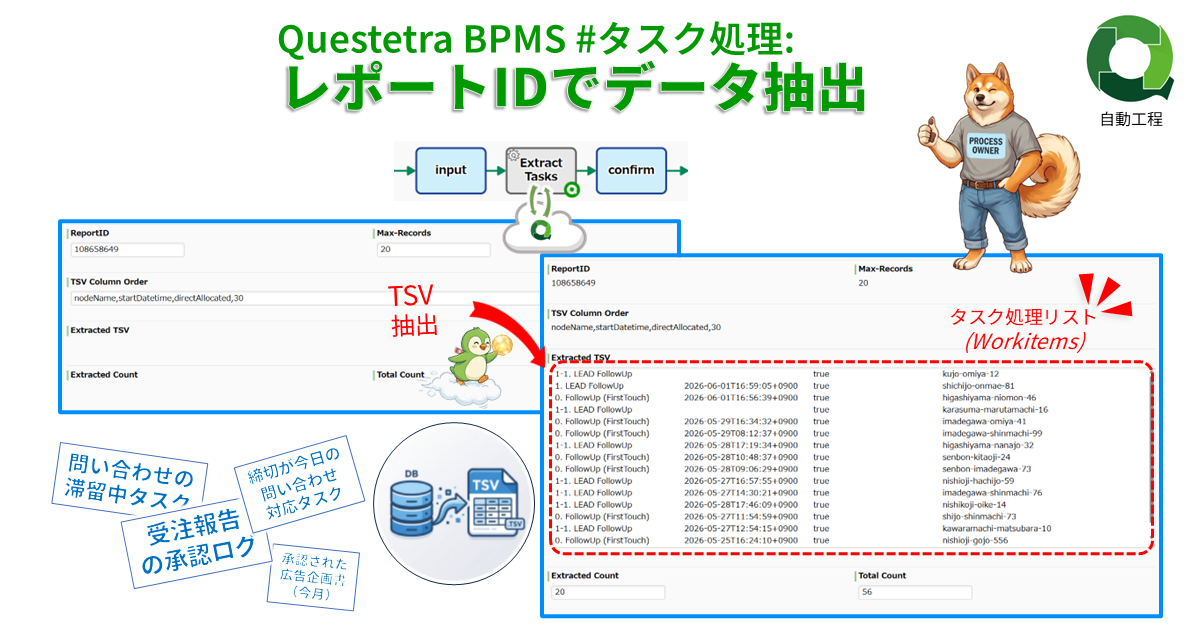
Questetra BPMS #タスク処理: レポートIDでデータ抽出
タスクデータ(ワークアイテム)をAPI経…
-

Questetra BPMS #ケース: レポートIDでデータ抽出
案件データ(ケースデータ)をAPI経由で…
-

#コラボチャット: クロススレッド投稿
任意のテキストをコラボチャット(Coll…
-

qGuide: OpenAI API にリクエスト (localStorage版)
文字列 “投入データ” を Respon…
-

Google スライド #複数ページ: PNGエクスポート
スライドページをPNG画像に変換し、ファ…
-
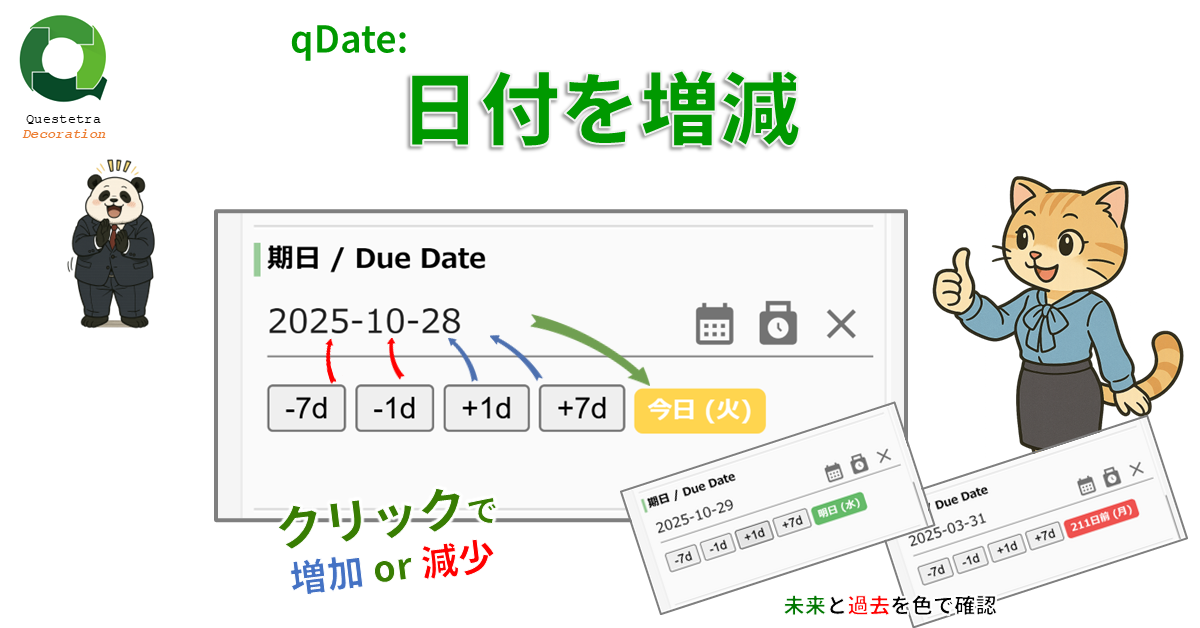
qDate: 日付を増減
日付型データ項目の入力を補助します。「+…
-

qGuide: OpenAI API に画像付でリクエスト
“投入ファイル” のファイル(Image…
-
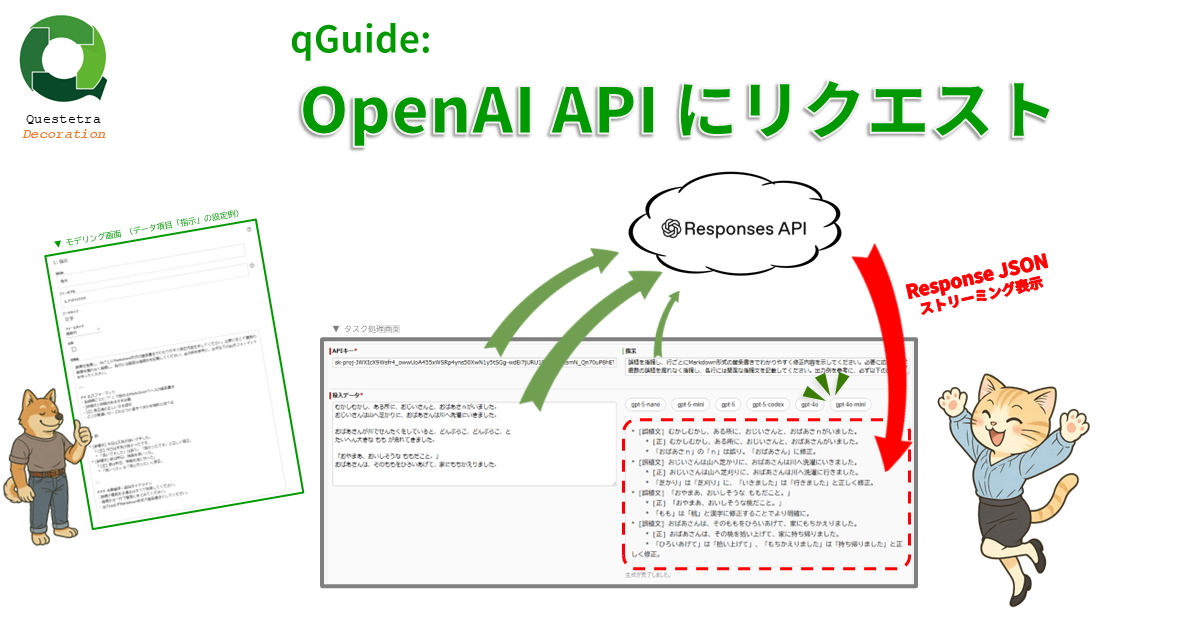
qGuide: OpenAI API にリクエスト
文字列 “投入データ” と文字列 “AP…
-
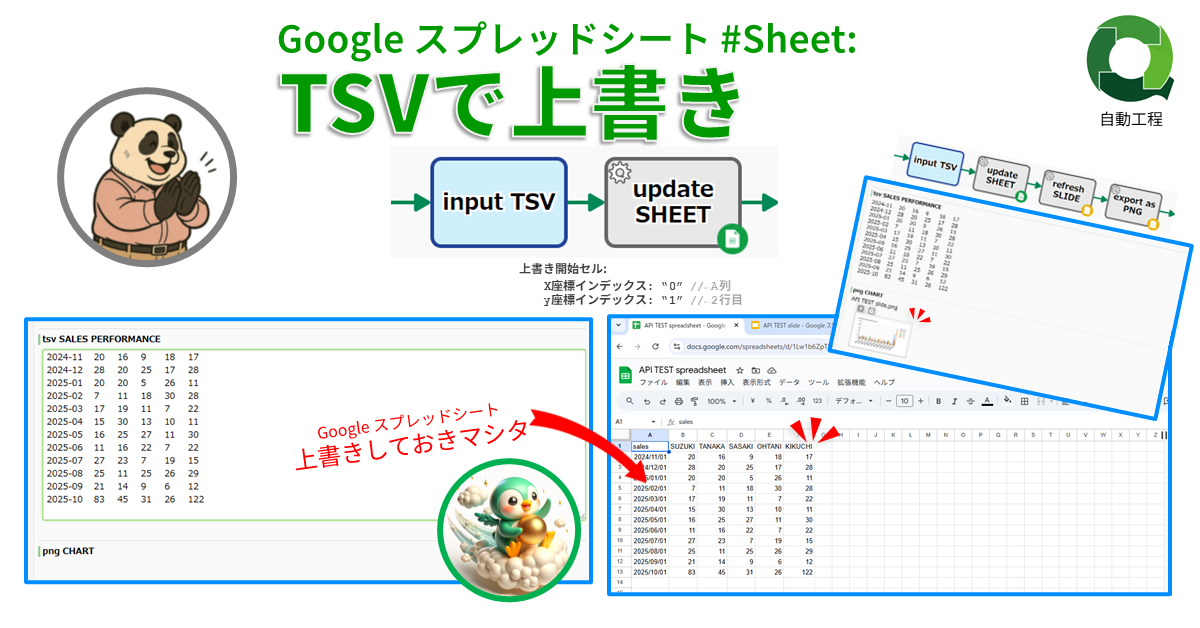
Google スプレッドシート #Sheet: TSVで上書き
指定シートの指定座標にTSVデータを貼り…
-
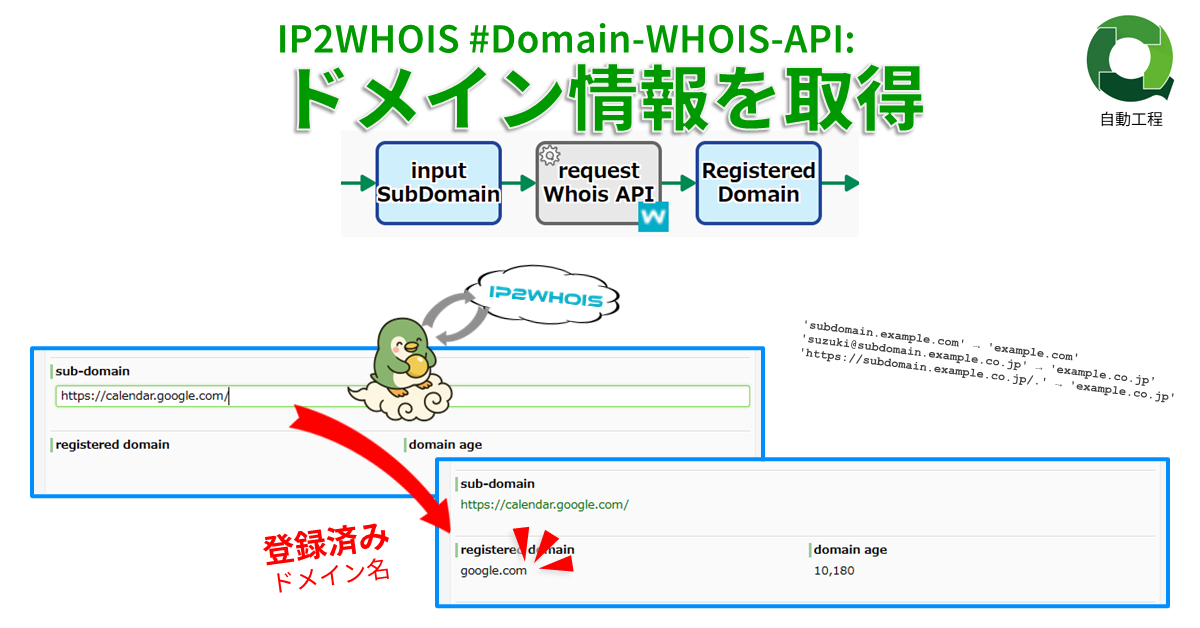
IP2WHOIS #Domain-WHOIS-API: ドメイン情報を取得
ドメイン形式文字列(サブドメインを含む)…
-
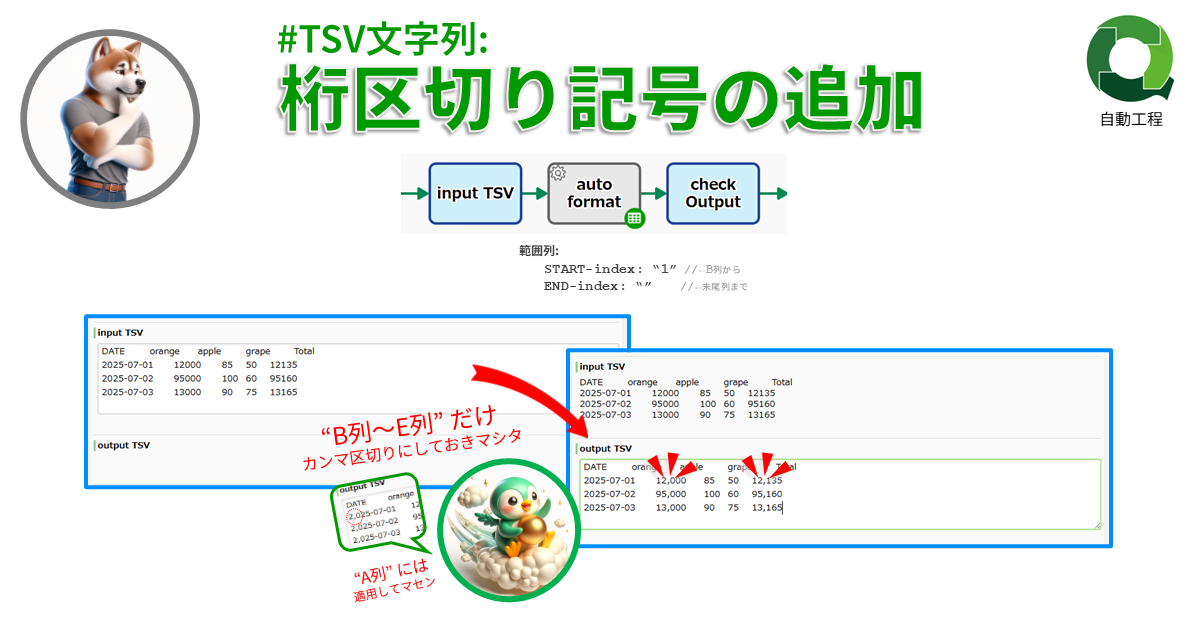
#TSV文字列: 桁区切り記号の追加
指定の列範囲に桁区切り書式を適用します。…
-

#TSV文字列: 範囲列の抽出
指定の列範囲を抽出します。抽出範囲はST…
-
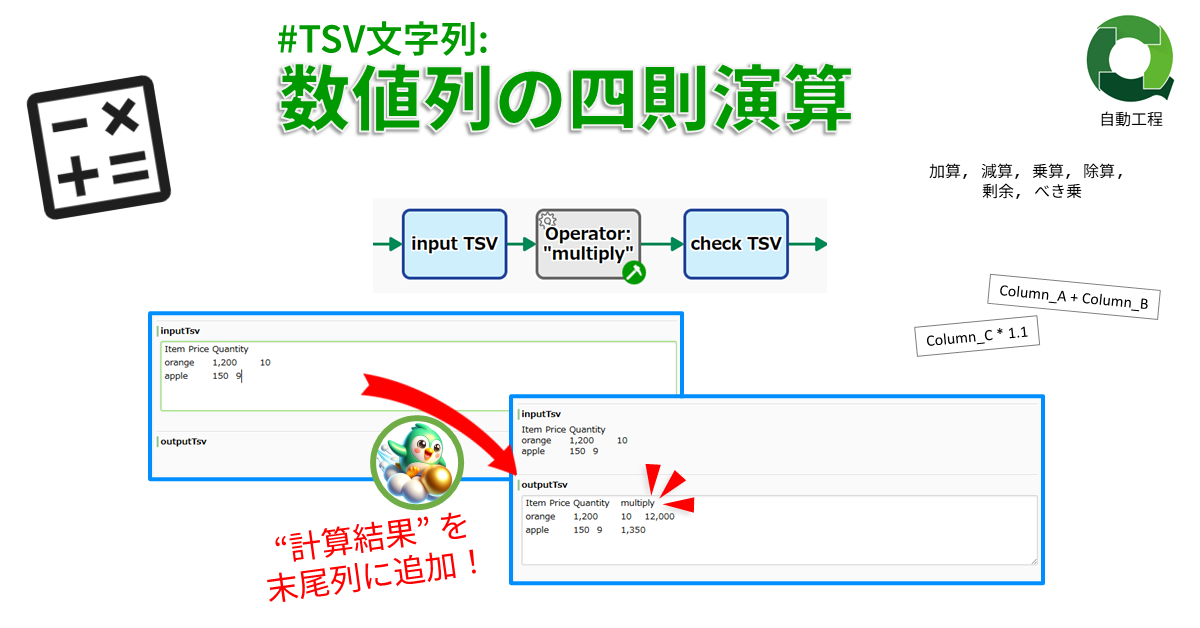
#TSV文字列: 数値列の四則演算
数値演算の結果を新しい列として追加します…
-
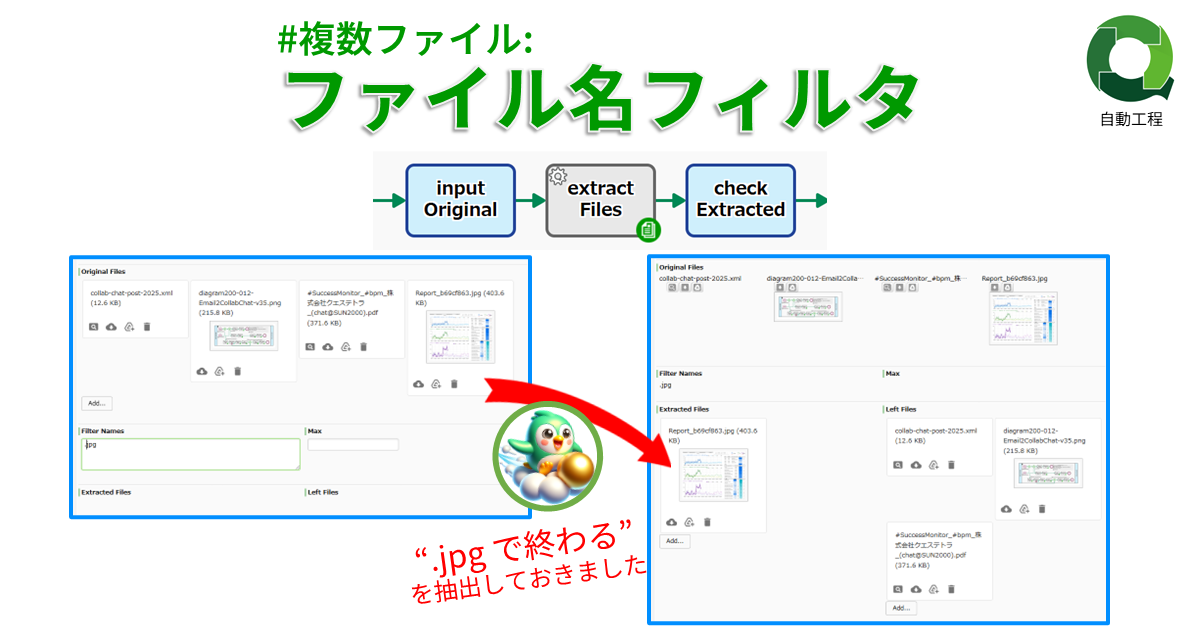
#複数ファイル: ファイル名フィルタ
ファイル型データに格納されているファイル…
-

#文字列: 正規表現でサブパターン抽出
正規表現にマッチする文字列を1つ抽出し、…
-
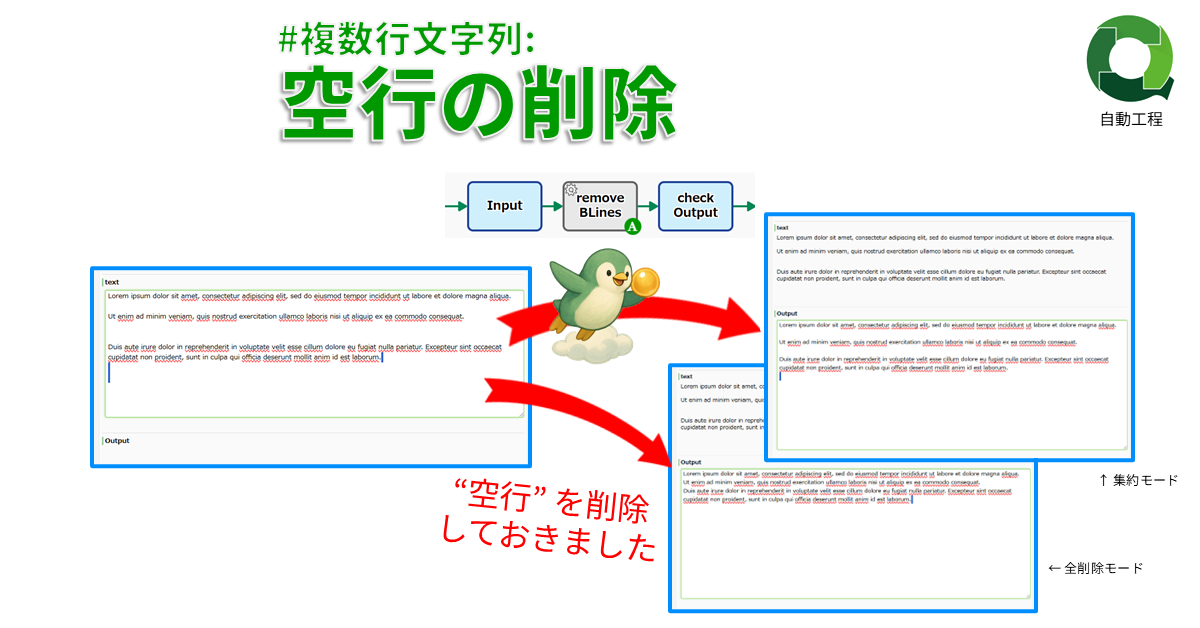
#複数行文字列: 空行の削除
空行を削除します。全ての空行を削除するモ…
-
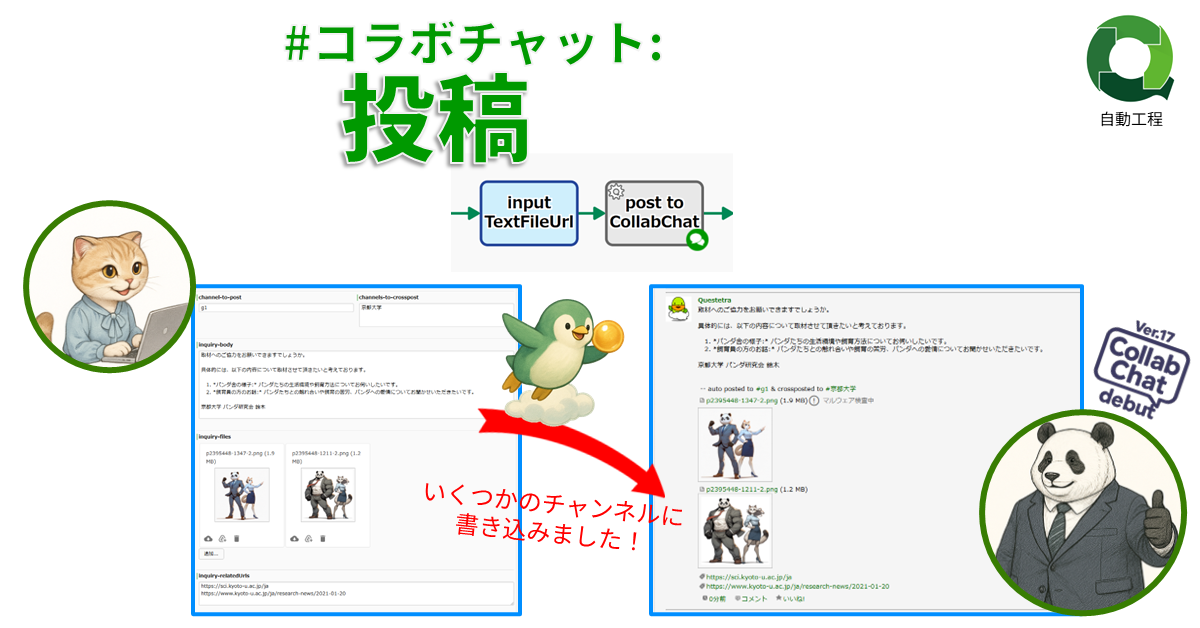
#コラボチャット: 投稿
任意テキストをコラボチャット(Colla…
-
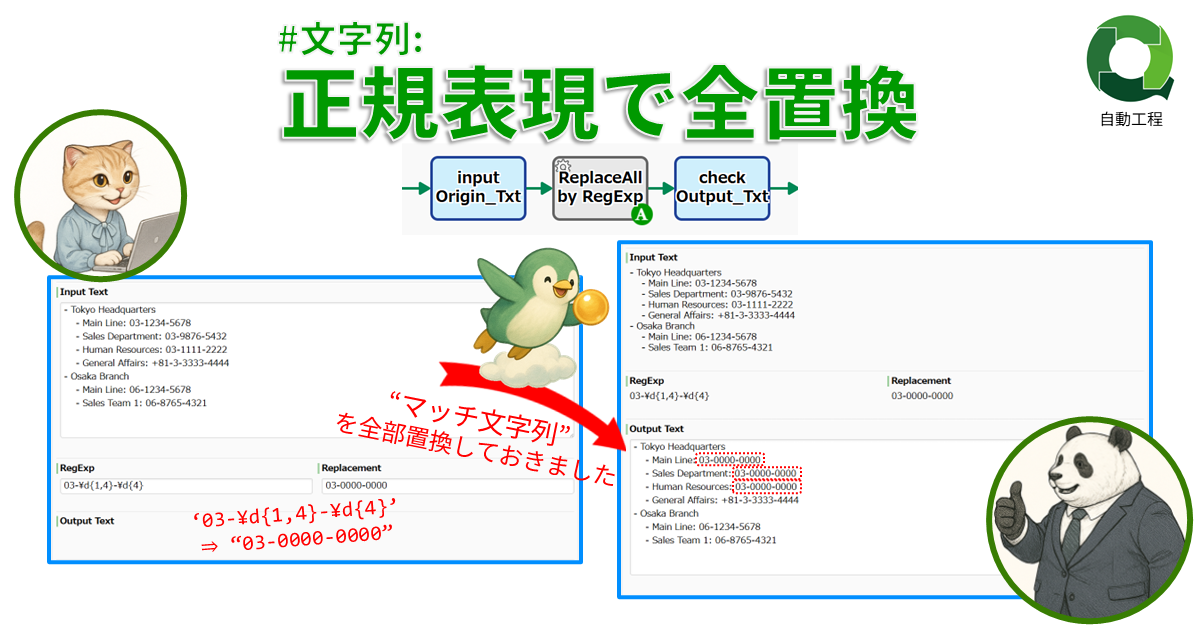
#文字列: 正規表現で全置換
正規表現にマッチする全ての文字列を指定文…
-

#TSV文字列: 各行ごとに正規表現で抽出
正規表現にマッチする文字列を各行ごとに抽…
-

#文字列: 正規表現で抽出
正規表現にマッチする文字列を全て抽出しま…
-
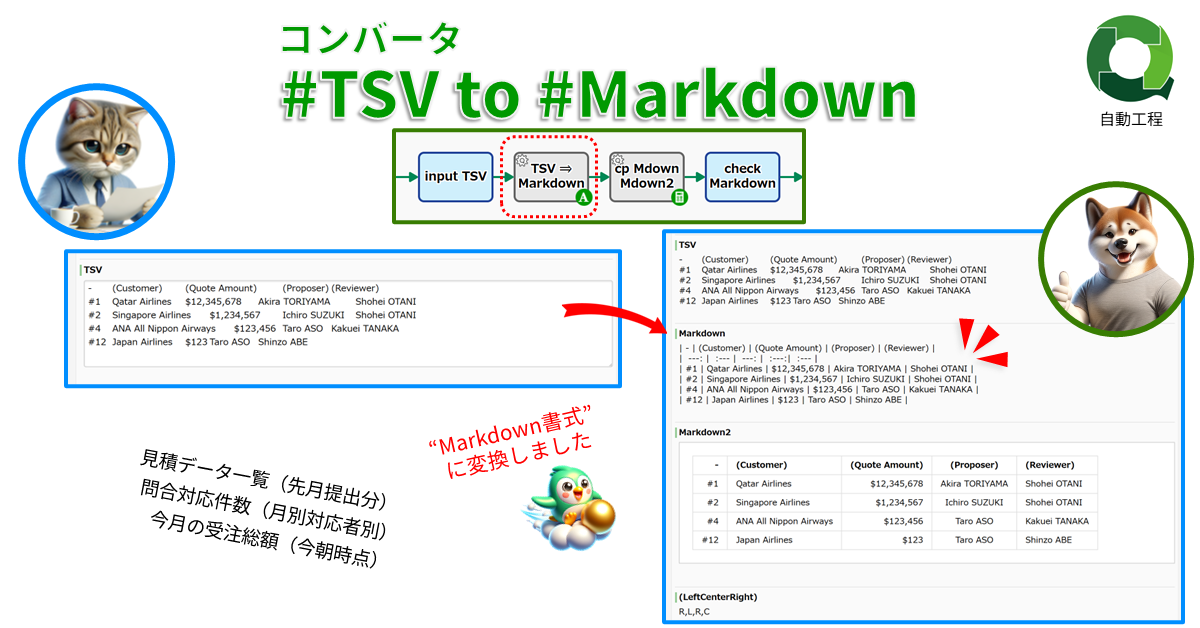
コンバータ: #TSV文字列 to #Markdown文字列
TSV文字列をMarkdown文字列に変…