TSV CSV
-

#TSV: テンプレート展開
プレースホルダー(”{{0}}”, “{…
-

日付 #TSV: 四半期ピボット生成
日付TSV内の日付列をY軸(四半期)、任…
-

日付 #TSV: 月次ピボット生成
日付TSV内の日付列をY軸(月次)、任意…
-
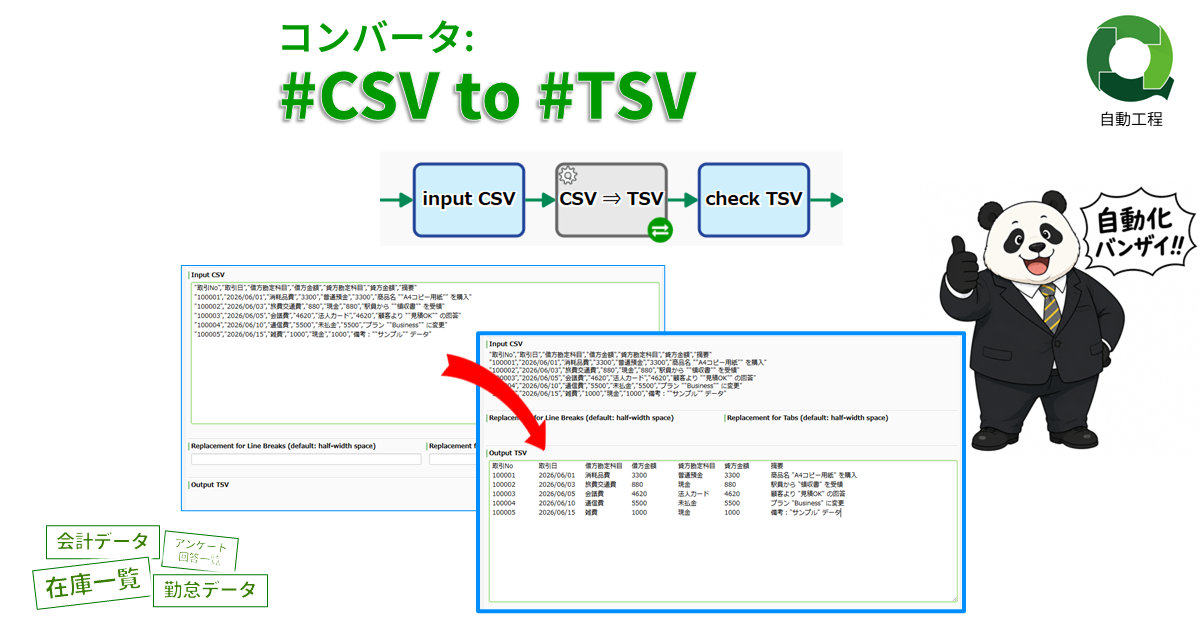
コンバータ: #CSV 文字列 to #TSV 文字列
CSV文字列をTSV文字列に変換します。…
-
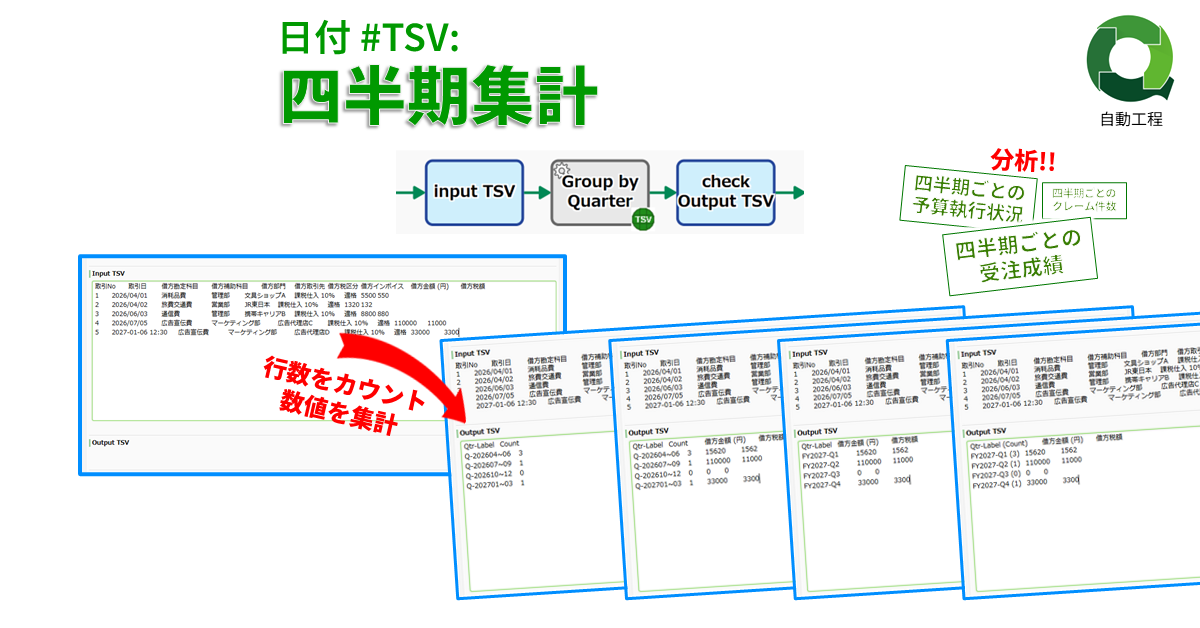
日付 #TSV: 四半期集計
日付TSV内の行数を四半期ごとにカウント…
-
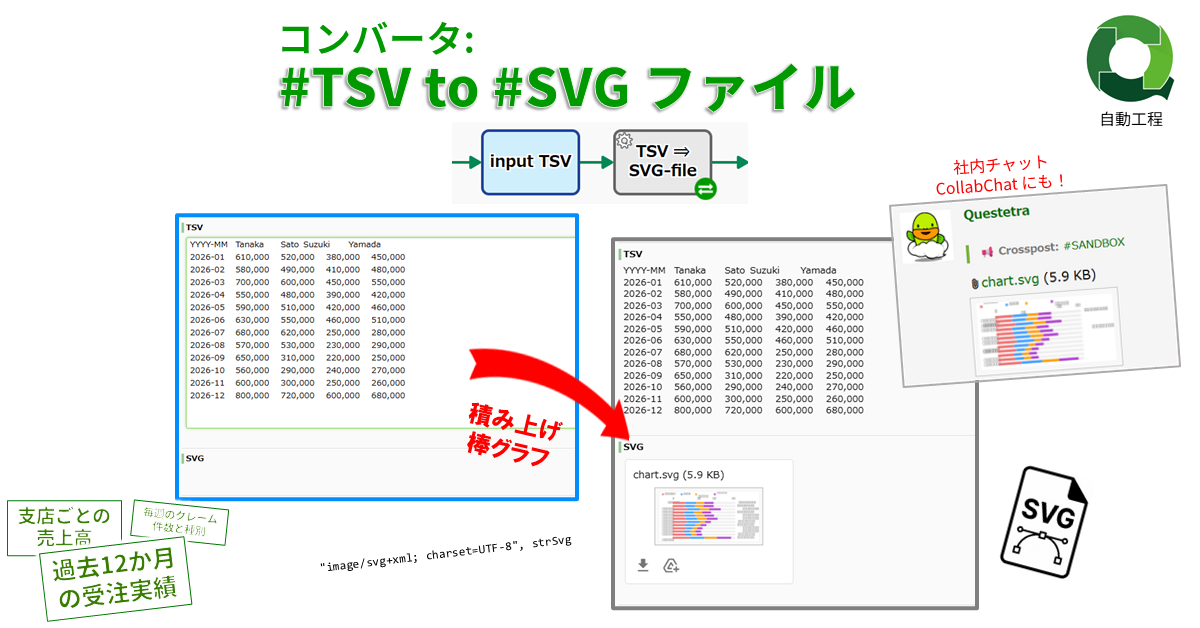
コンバータ: #TSV 文字列 to #SVG ファイル
数値TSV文字列を「積み上げ棒グラフのS…
-

コンバータ: #TSV文字列 to #MdChart文字列
数値TSV文字列を「Markdownに埋…
-
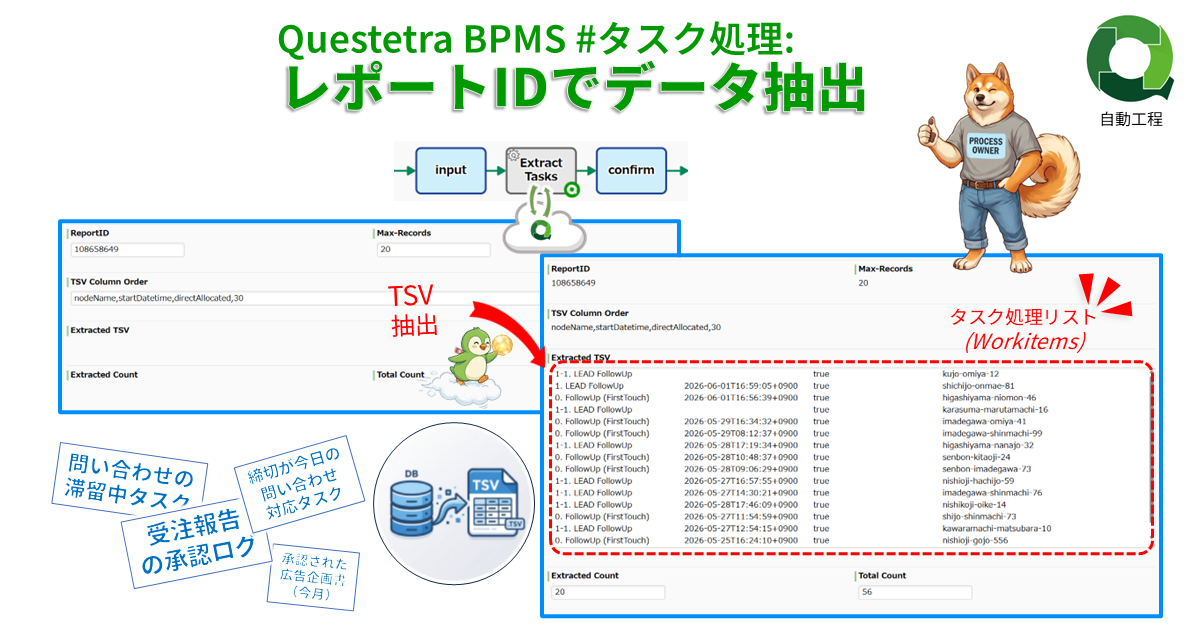
Questetra BPMS #タスク処理: レポートIDでデータ抽出
タスクデータ(ワークアイテム)をAPI経…
-

Questetra BPMS #ケース: レポートIDでデータ抽出
案件データ(ケースデータ)をAPI経由で…
-

Questetra BPMS #案件: 保存済フィルタでTSV一括抽出
指定した保存済フィルタに一致するプロセス…
-
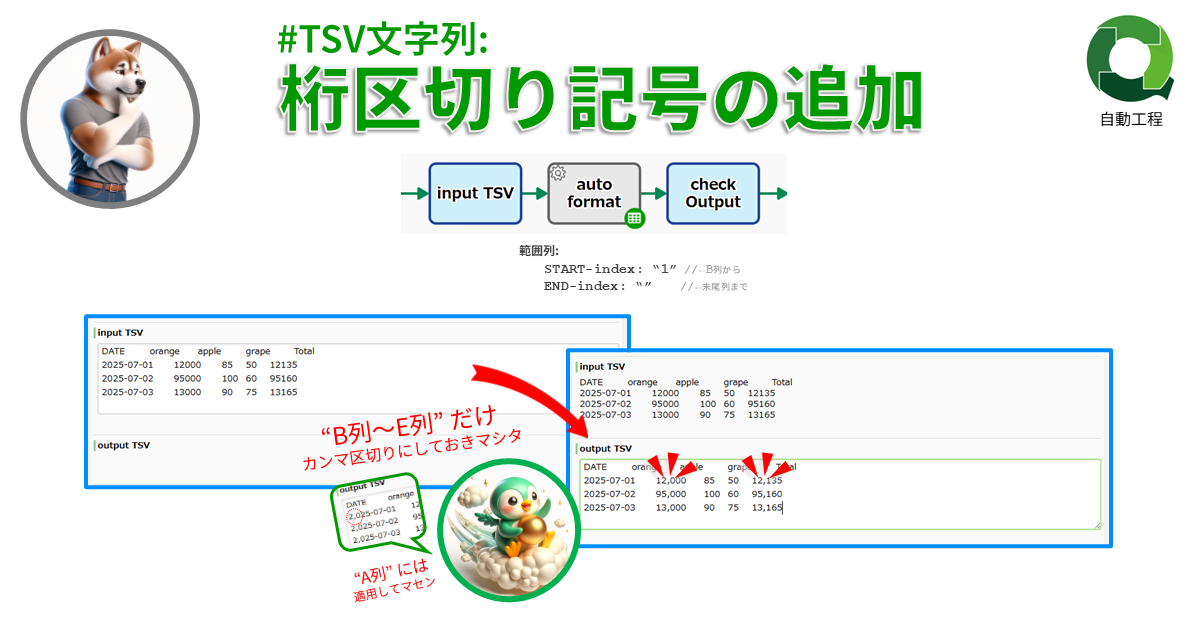
#TSV文字列: 桁区切り記号の追加
指定の列範囲に桁区切り書式を適用します。…
-

#TSV文字列: 範囲列の抽出
指定の列範囲を抽出します。抽出範囲はST…
-
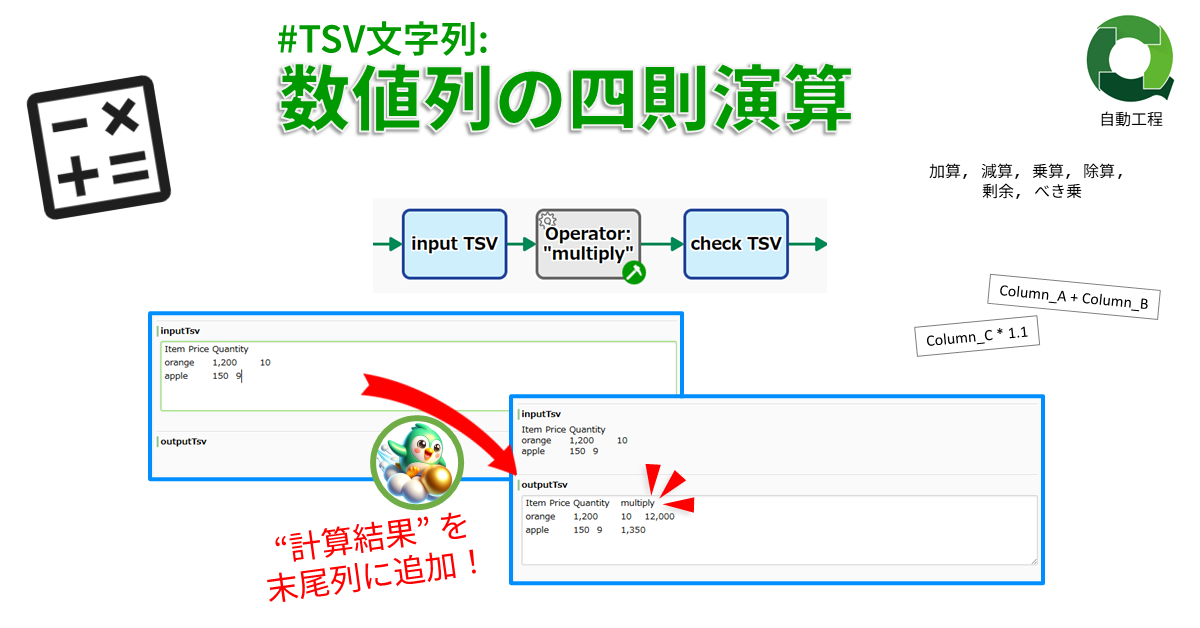
#TSV文字列: 数値列の四則演算
数値演算の結果を新しい列として追加します…
-
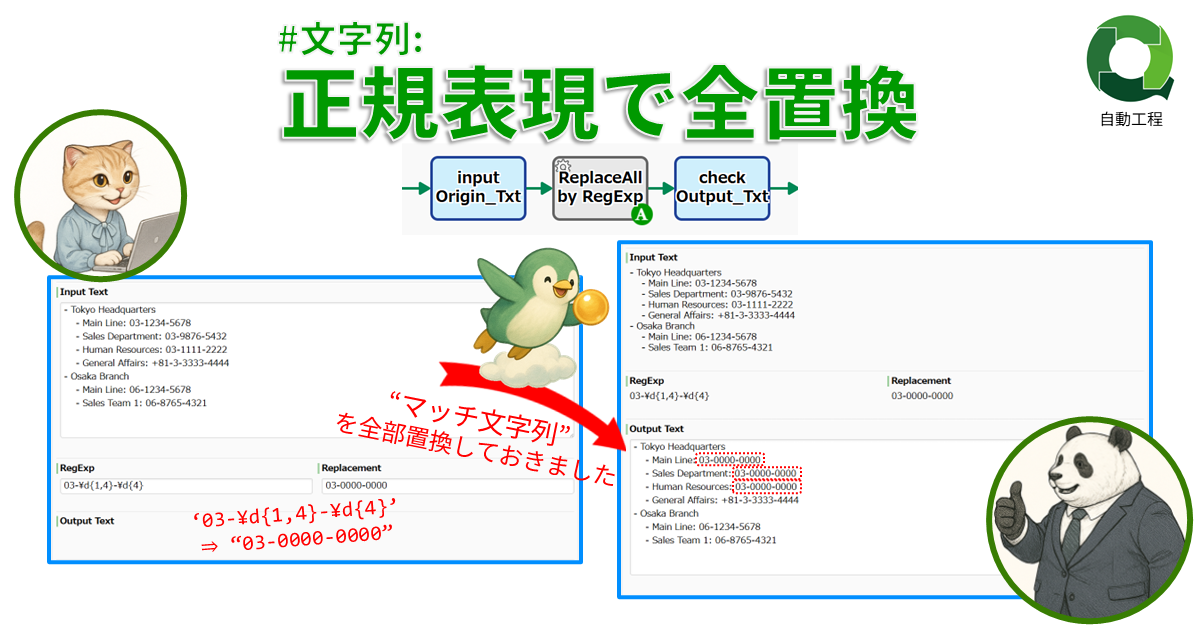
#文字列: 正規表現で全置換
正規表現にマッチする全ての文字列を指定文…
-

#TSV文字列: 各行ごとに正規表現で抽出
正規表現にマッチする文字列を各行ごとに抽…
-

#文字列: 正規表現で抽出
正規表現にマッチする文字列を全て抽出しま…
-
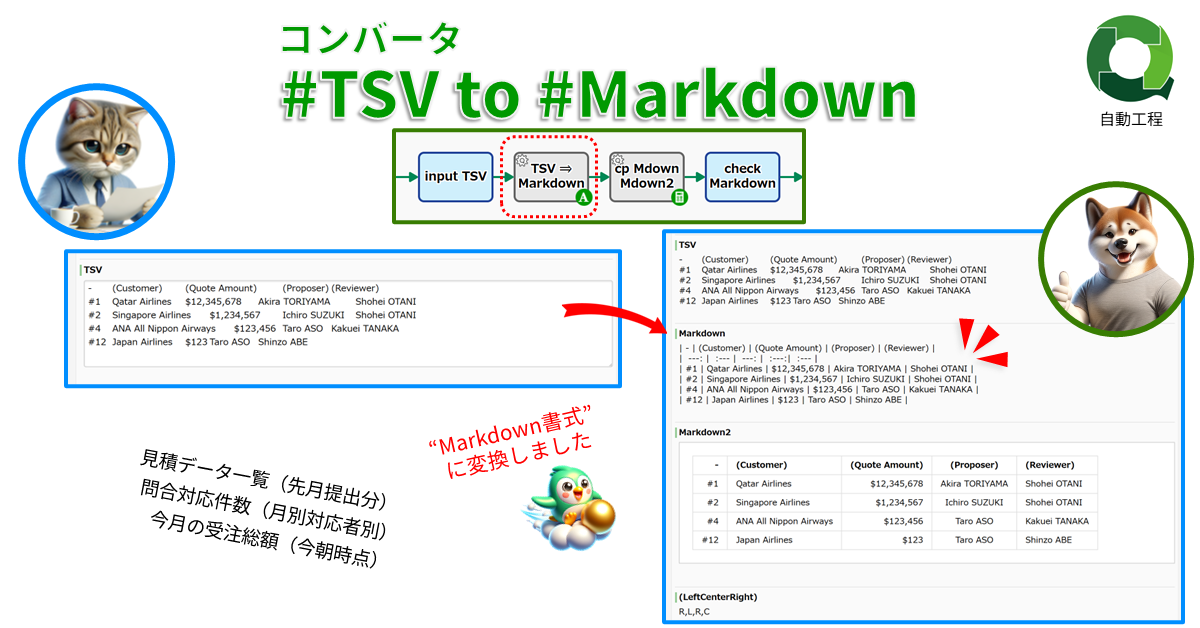
コンバータ: #TSV文字列 to #Markdown文字列
TSV文字列をMarkdown文字列に変…
-

TSV文字列: セルデータの抽出
指定セルの値を抽出します。セルはA1表記…
-
CSV データ更新
文字型(複数行)に入力された CSV /…
-

コンバータ (TSV ファイル to テーブル型データ)
この工程は、テーブル型データ項目の値を、…
-
コンバータ(テーブル型データ to Excel-CSV ファイル)
この工程は、テーブル型データ項目の値を …