アドオン
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
■
-
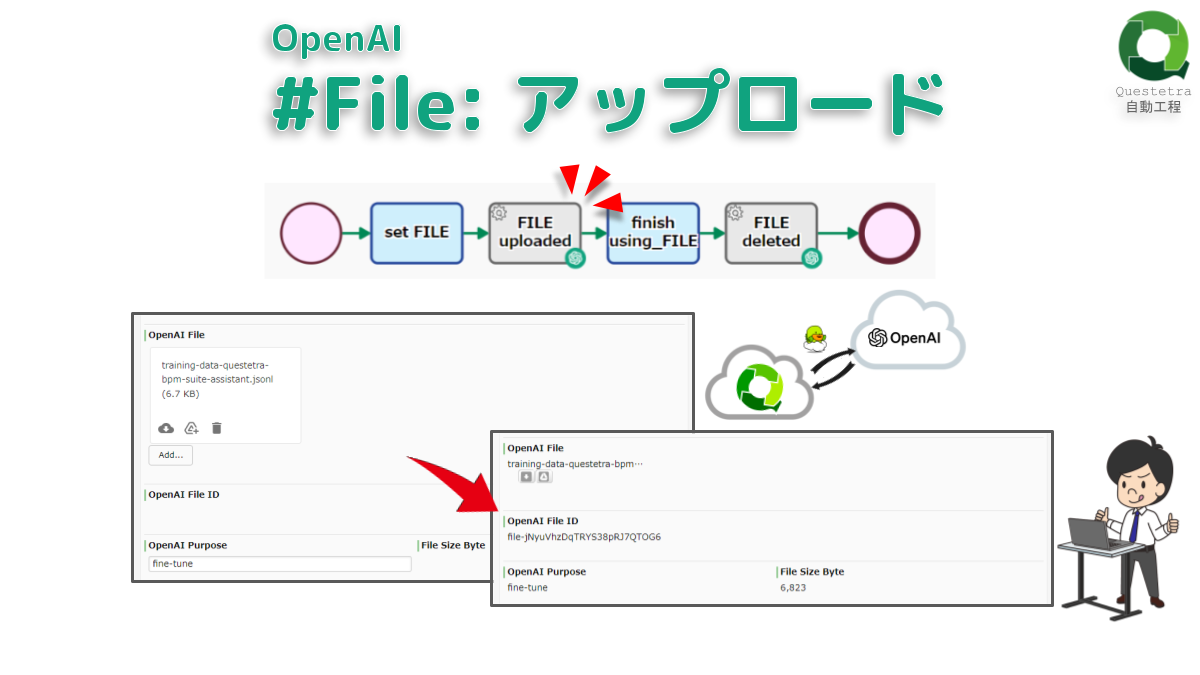
OpenAI #File: アップロード
ファイルを OpenAI API サーバ…
-

Dropbox アップロード
Dropbox の指定ディレクトリにファ…
-

Image-Charts: QR Code, 生成
Image-Chart QRCode を…
-
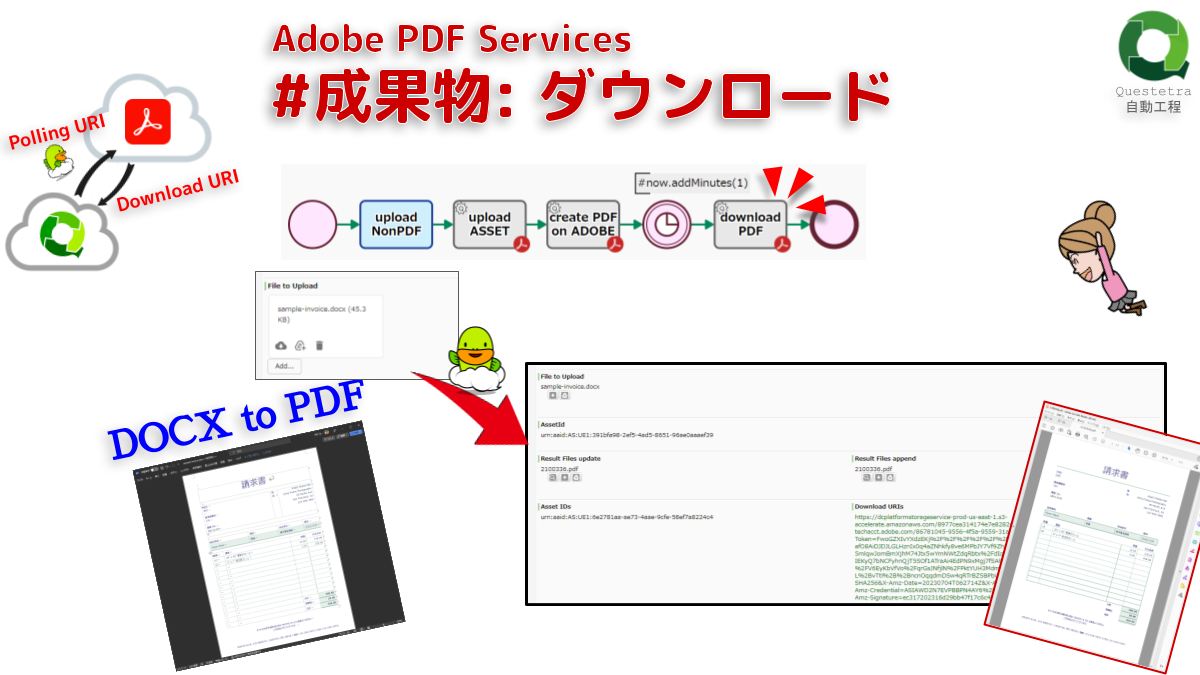
Adobe PDF Services #成果物: ダウンロード
上流で取得された Polling-URI…
-

Adobe PDF Services #NonPDF: PDFを作成
PDF Services 用の内部ストレ…
-

Adobe PDF Services #ASSET: 削除
PDF Services 用の内部ストレ…
-
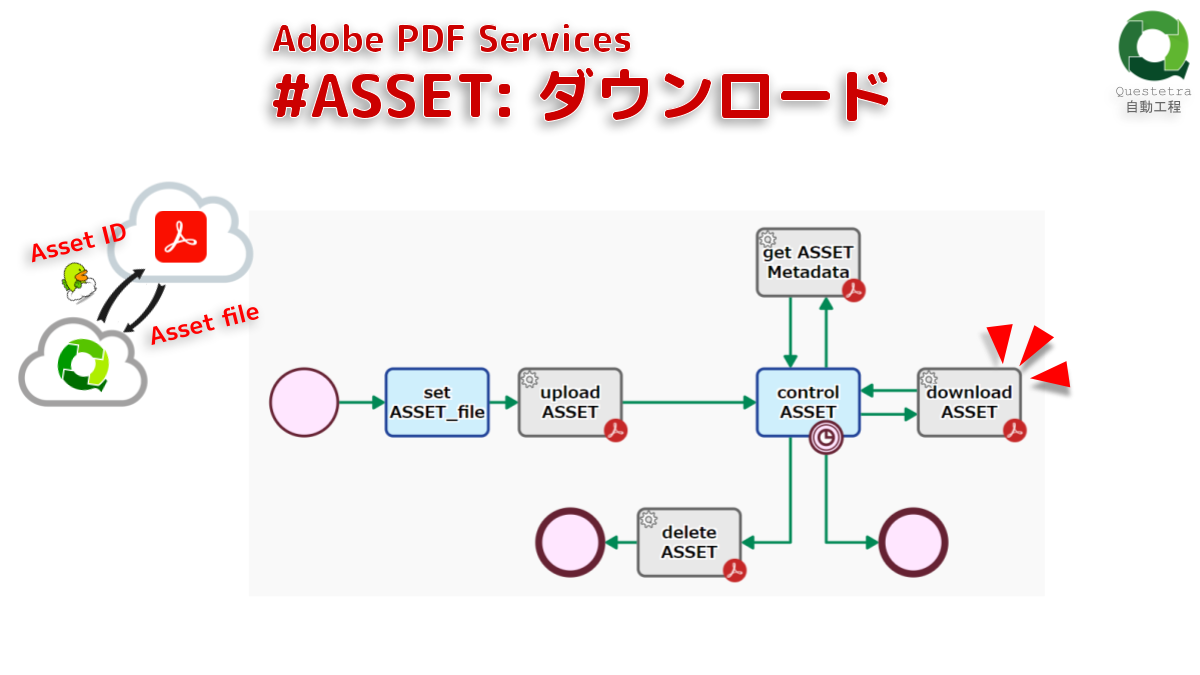
Adobe PDF Services #ASSET: ダウンロード
PDF Services 用の内部ストレ…
-

Adobe PDF Services #ASSET: メタデータ取得
PDF Services 用の内部ストレ…
-

Adobe PDF Services #ASSET: アップロード
ASSET(各種素材ファイル)を PDF…
-

コンバータ: Email文字列 to Quser
Email文字列(文字列データ)をユーザ…
-

LINE Notifyでメッセージ投稿
LINE Notifyを通してLINEグ…
-
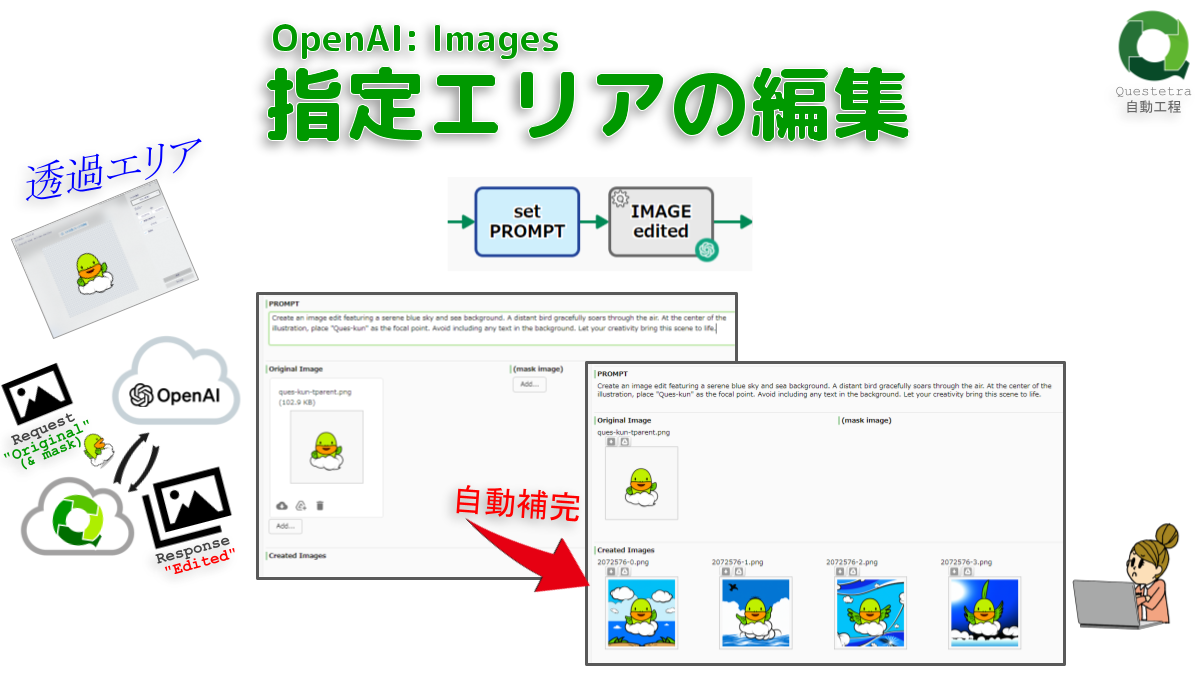
OpenAI #Images: 指定エリアの編集
画像内の「透過エリア」を、指示文(PRO…
-
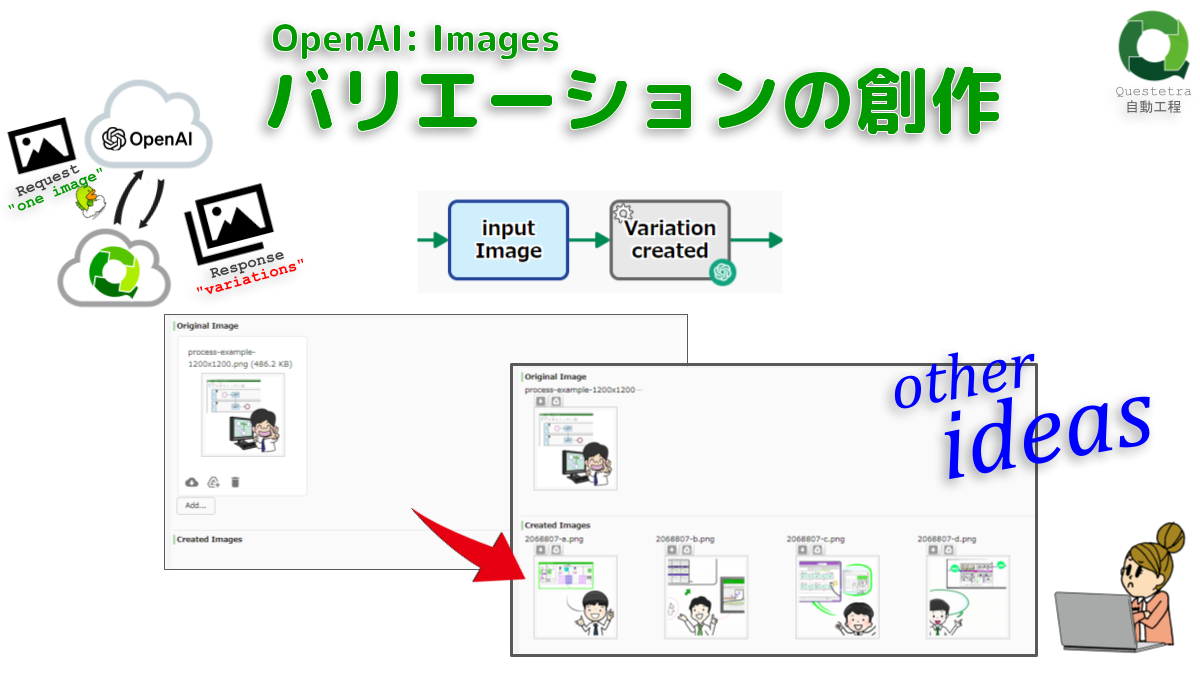
OpenAI #Images: バリエーションの創作
元画像のバリエーション(類似画像・変形画…
-

OpenAI #Images: 生成
指示文(PROMPT)に対する画像を生成…
-
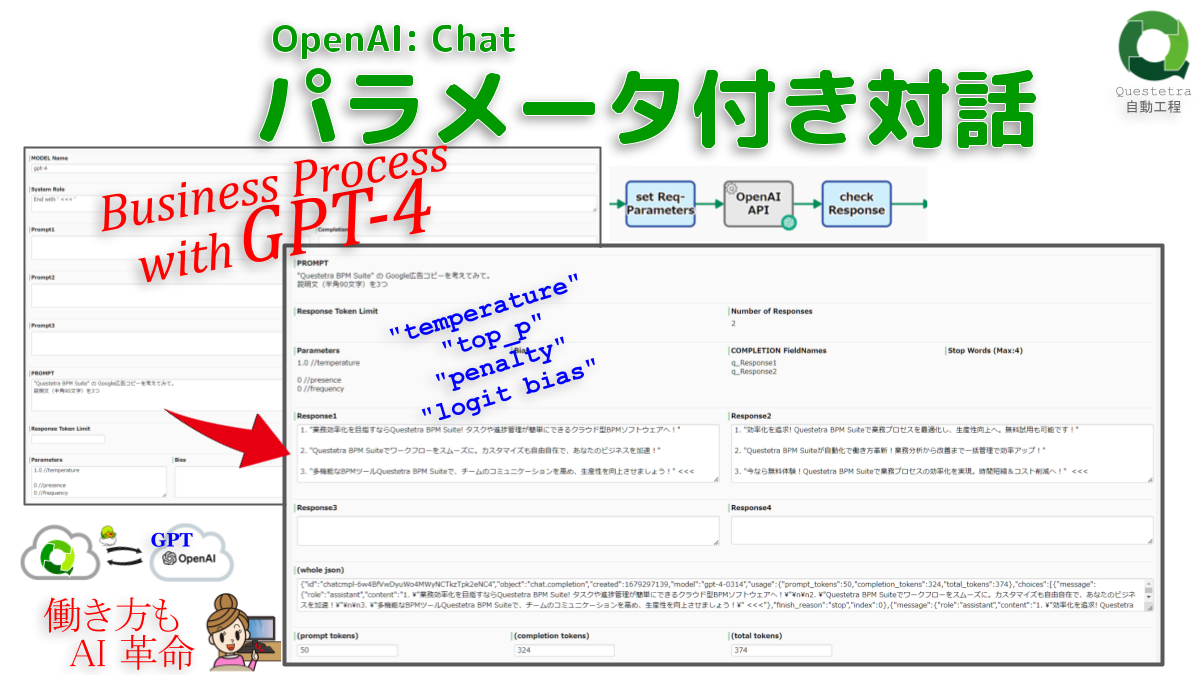
OpenAI #Chat: パラメータ付き対話
OpenAI API (ChatGPT)…
-
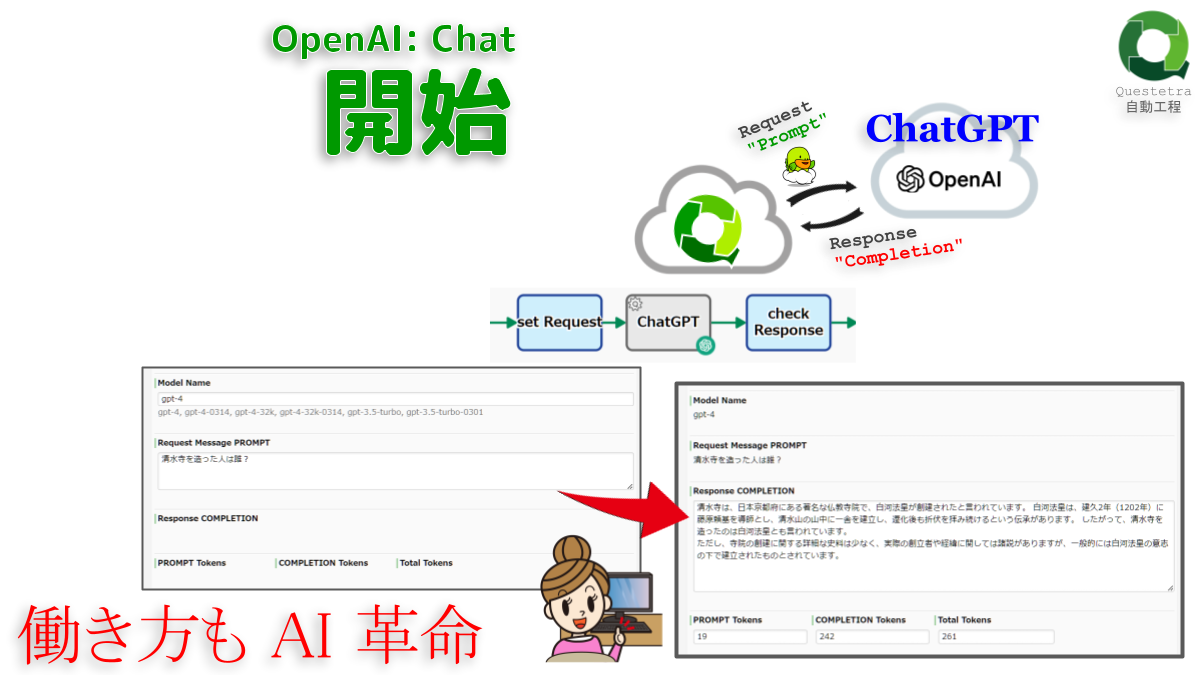
OpenAI #Chat: 開始
OpenAI API (ChatGPT)…
-

OpenAI #Audio: WebVTT形式で文字起こし
音源ファイルから字幕ファイル WebVT…
-

OpenAI #Audio: 英文へ翻訳
音声データから英文テキストに翻訳します。…
-

OpenAI #Audio: 文字起こし
音声ファイルから文字を起こします。Ope…
-
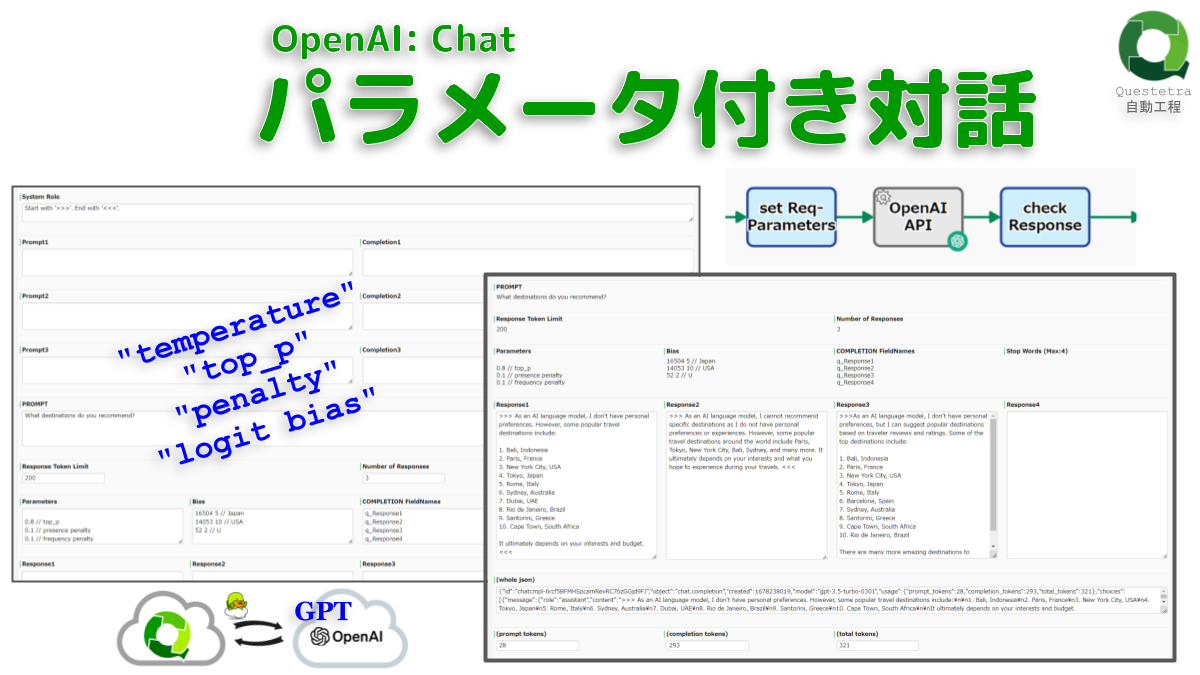
OpenAI: Chat, パラメータ付き対話
OpenAI API (ChatGPT)…
-
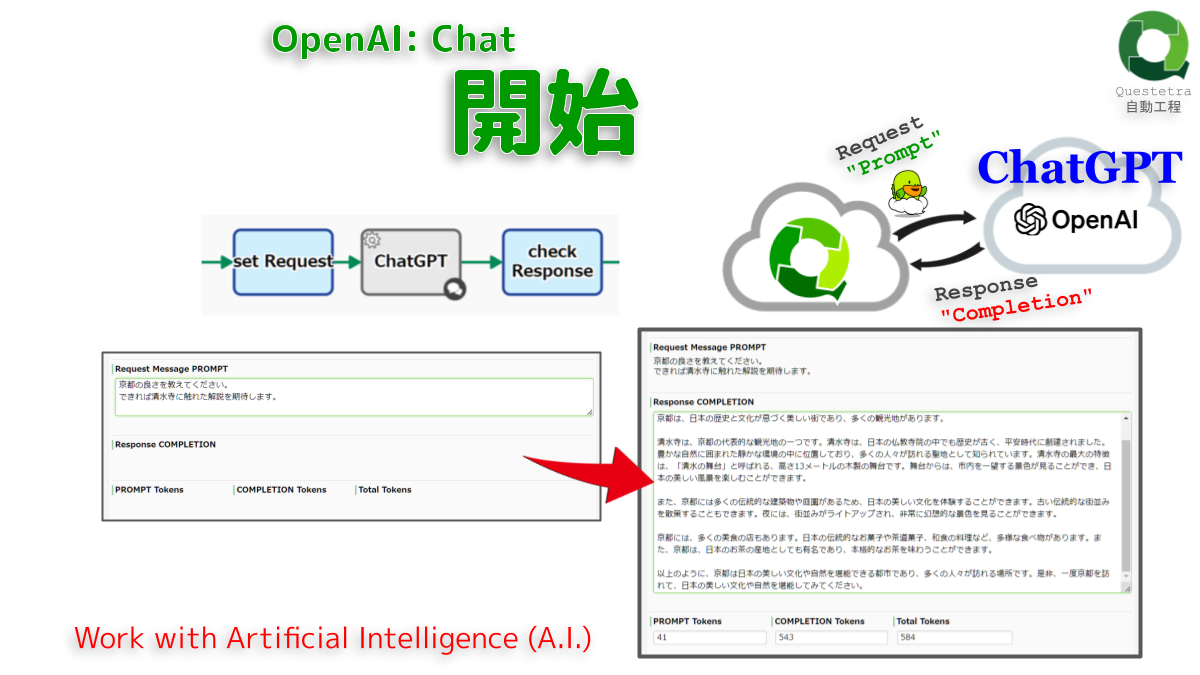
OpenAI: Chat, 開始
OpenAI API (ChatGPT)…
タグクラウド
Adobe PDF Services APIauthSetting()クラウド制御マネーフォワード クラウド会計マーケティングbasic(id,passwd)bearer(oauth2Token)申請承認経費精算翻訳依頼Date()Dropbox APIEasy-Config Addon見積対応feedServicefileRepositoryGoogle Admin SDK Directory API v1Google Analytics Data API v1Google Analytics Reporting API v4Google Calendar API v3Google Docs APIGoogle Drive API v3Google Fit APIGoogle Sheets API v4Google Slides APIGoogle WorkspaceHello-World AddonHTMLメールhttpClientImage-Charts APIitemDaoItemViewJSON.parse()JSON.stringify()kintone APIListArrayMarkdownMathMicrosoft 365Microsoft OneDriveNewQfileOpenAI API受注対応PayPal Invoicing APIQfileViewqgroupDaoqroleDaoQuestetra System Settings APIQuestetra Workflow APIquserDaoRegExp定型業務SalesforceSalesforce APISlack Web APIStripe APITSV CSVWordPress.com APIWorkflow AutomationXPath勤怠管理問合対応広告宣伝情報発信情報管理支援受付業務報告代金請求