Easy-Config Addon
-

複数行文字列: 行数の取得
テキストの行数を取得します。末尾の改行コ…
-

Image-Charts: QR Code, 生成
Image-Chart QRCode を…
-

コンバータ: Email文字列 to Quser
Email文字列(文字列データ)をユーザ…
-
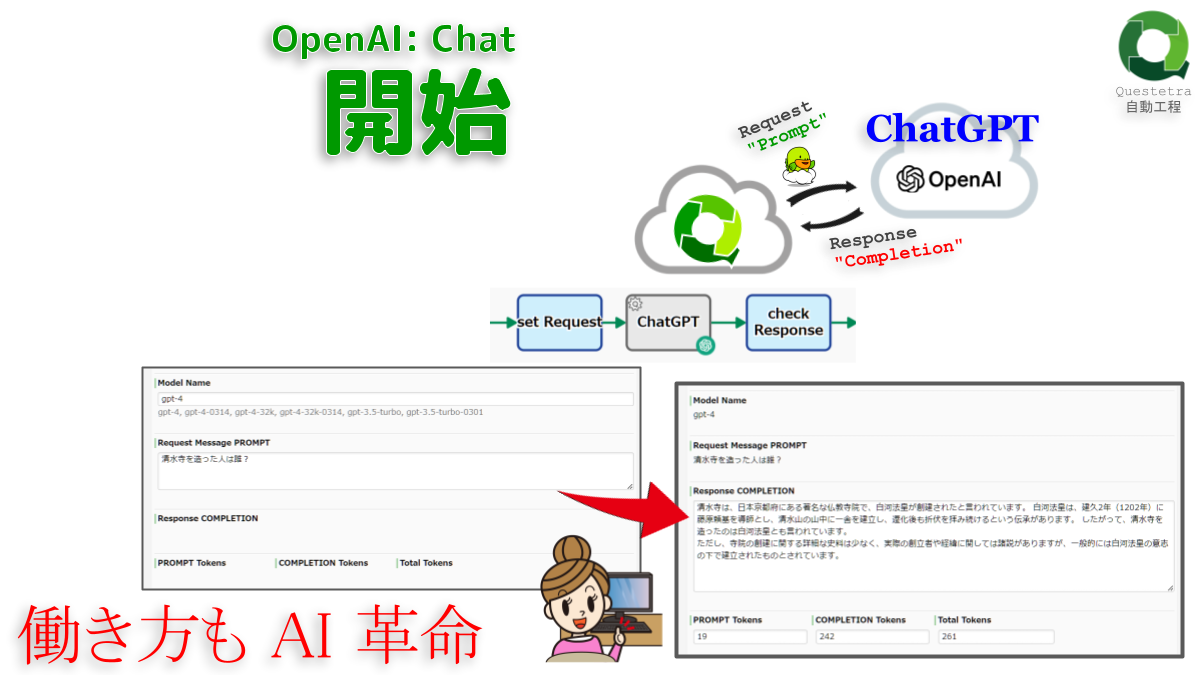
OpenAI #Chat: 開始
OpenAI API (ChatGPT)…
-
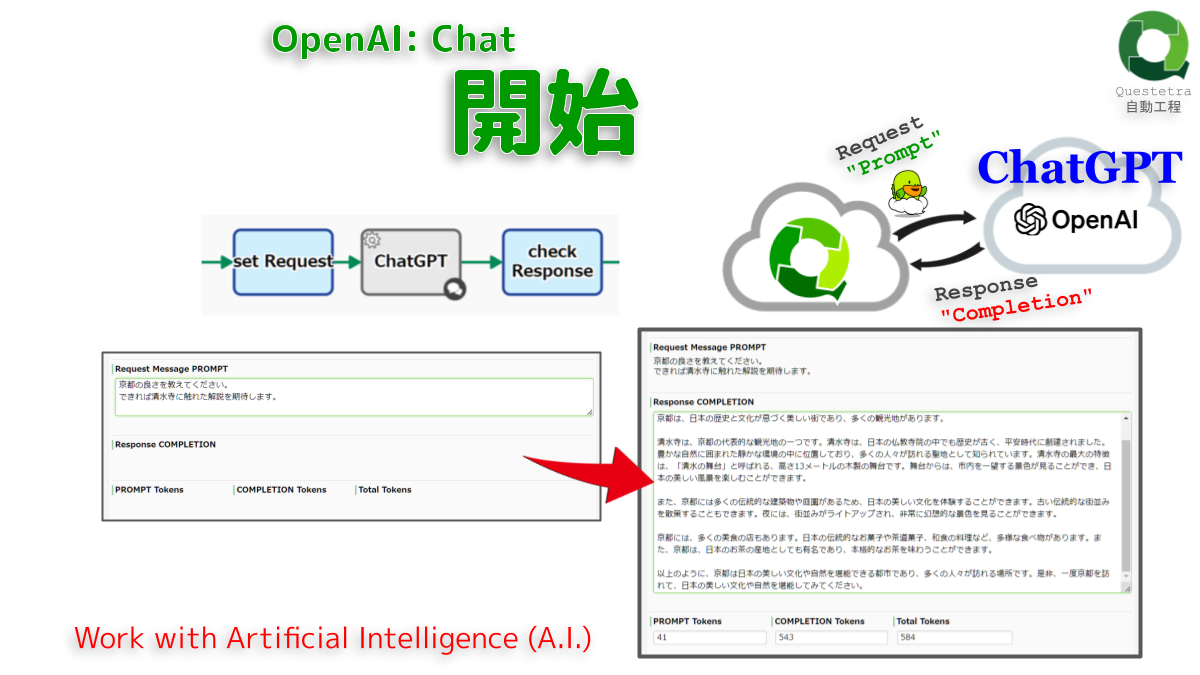
OpenAI: Chat, 開始
OpenAI API (ChatGPT)…
-

ファイル, 複製
ファイル型データを複製します。ファイル型…
-
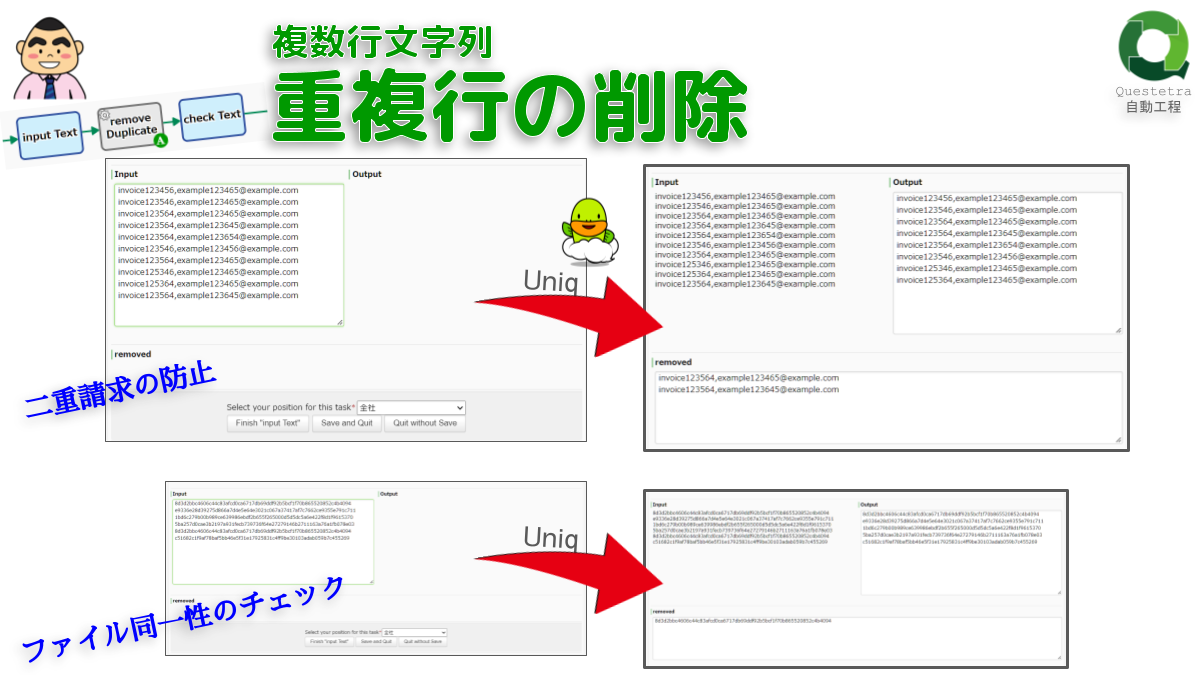
複数行文字列, 重複行の削除
全ての重複行を抽出し、削除します。正順モ…
-
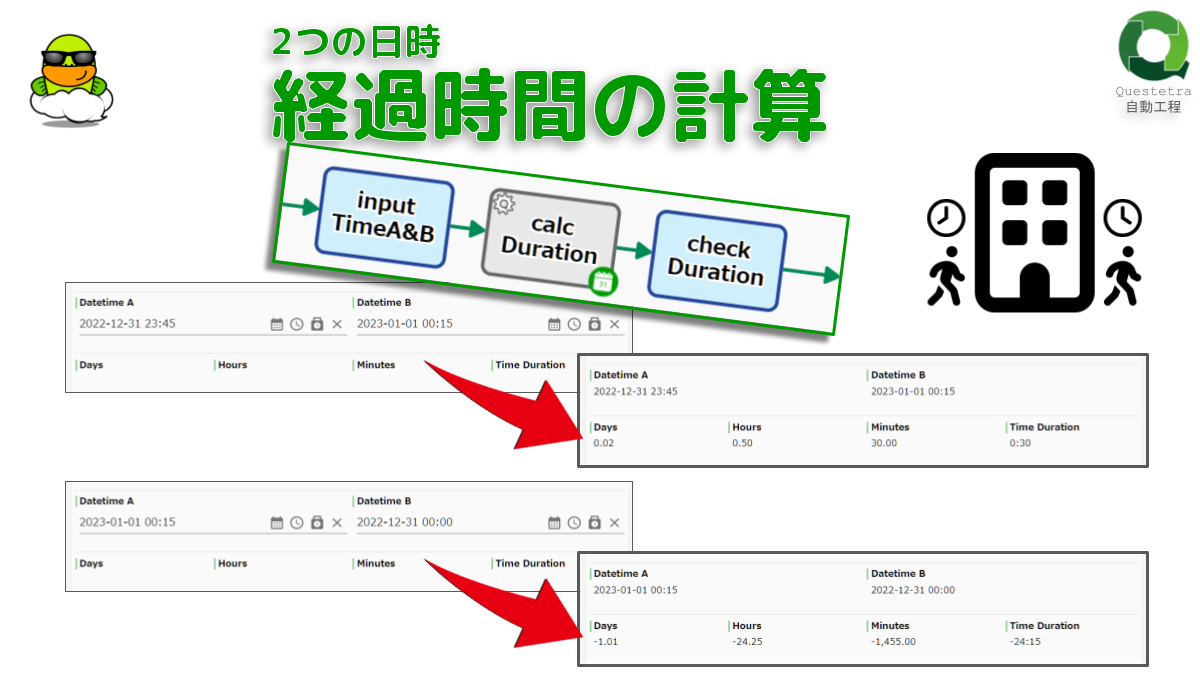
2つの日時, 経過時間の計算
日時Aから日時Bまでの経過時間を算出しま…
-
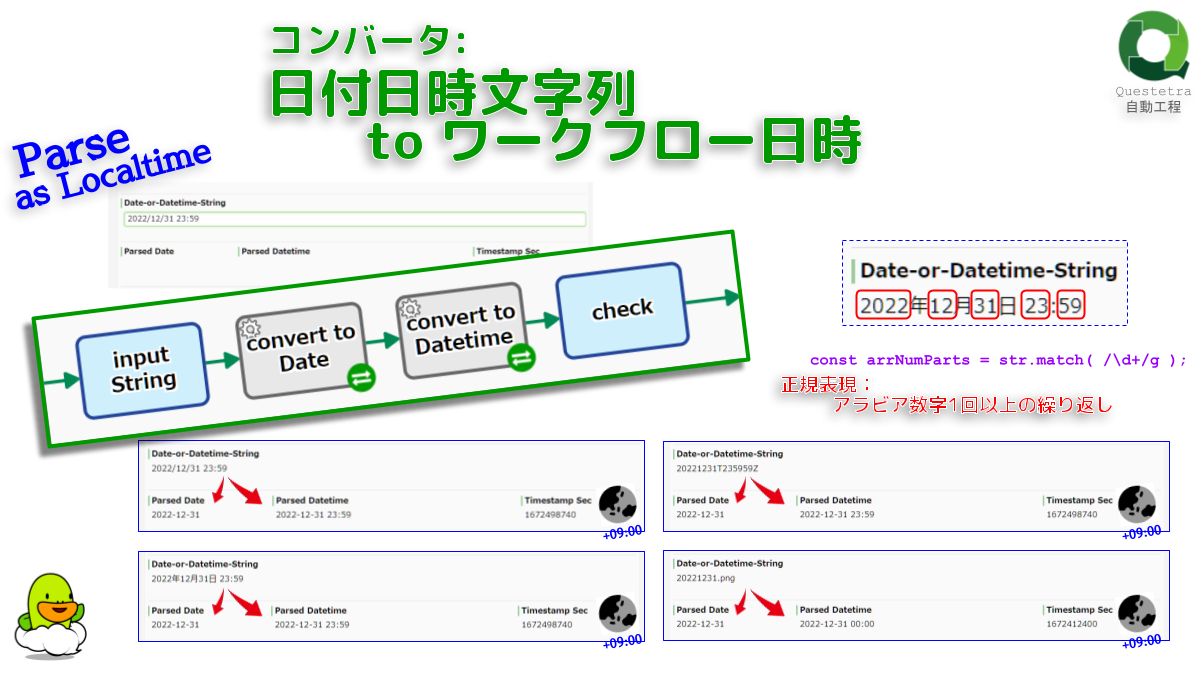
コンバータ: 日付日時文字列 to ワークフロー日時
“2022-12-31” や “2022…
-

ファイル,複数ファイル型データ項目をまとめて複製
ファイル型データを複製します。複数のファ…
-
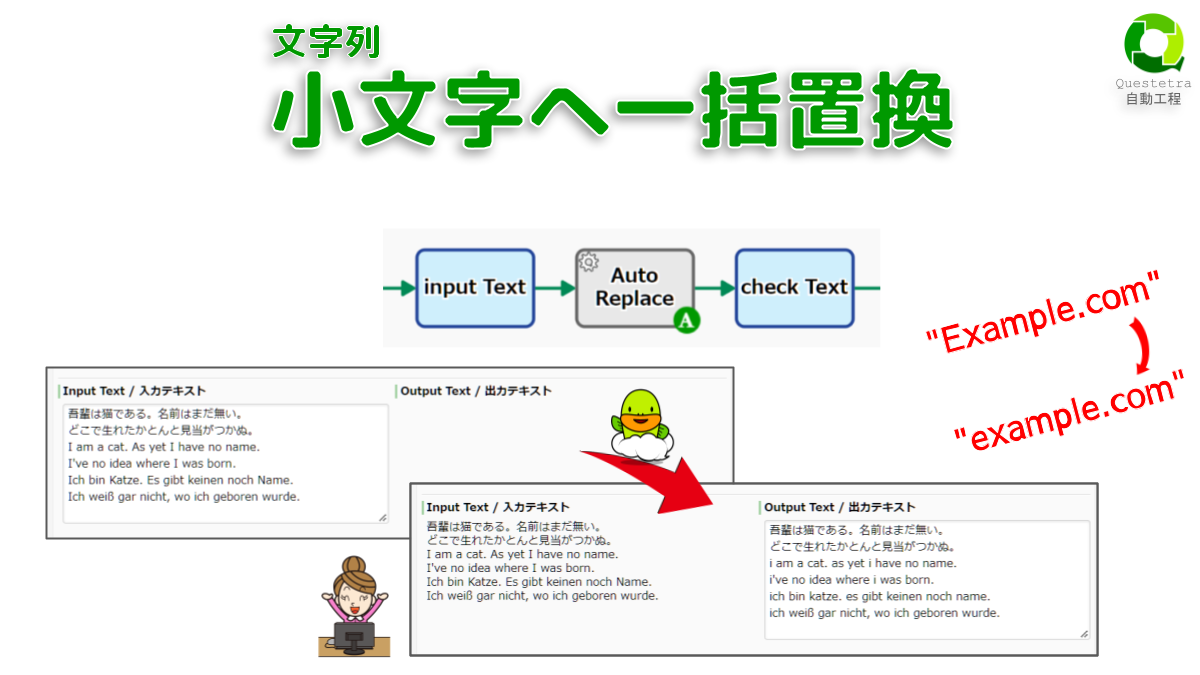
文字列: 小文字へ一括置換
テキスト内にある全ての大文字を小文字に置…
-
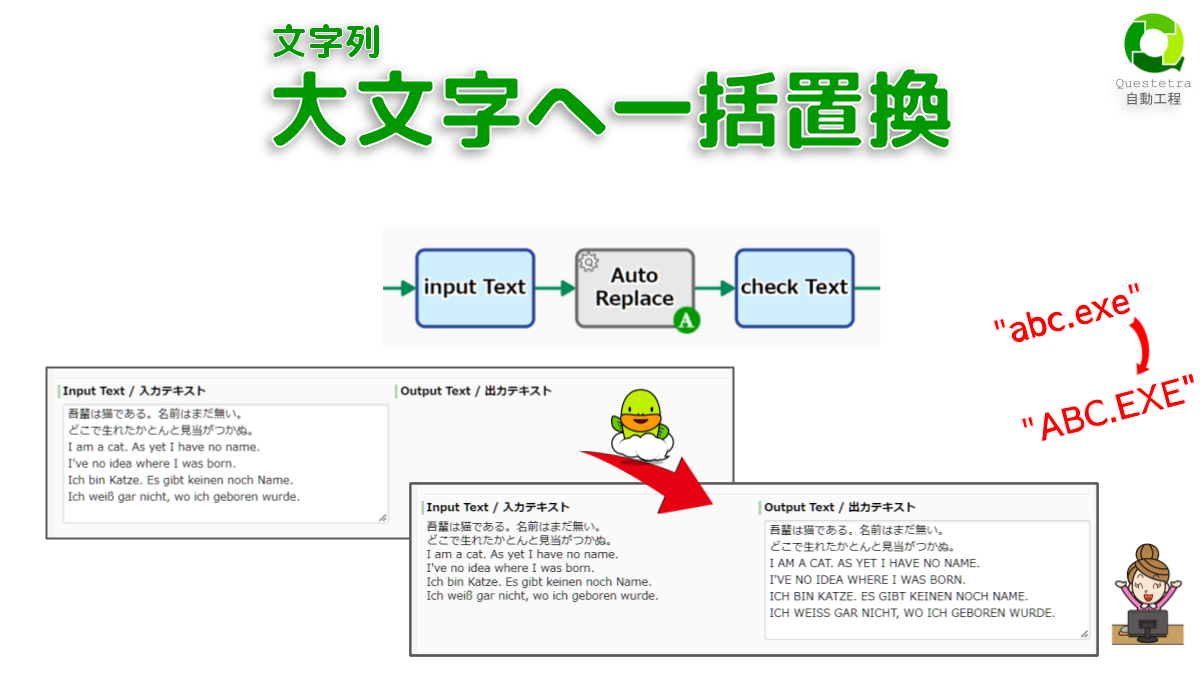
文字列: 大文字へ一括置換
テキスト内にある全ての小文字を大文字に置…
-
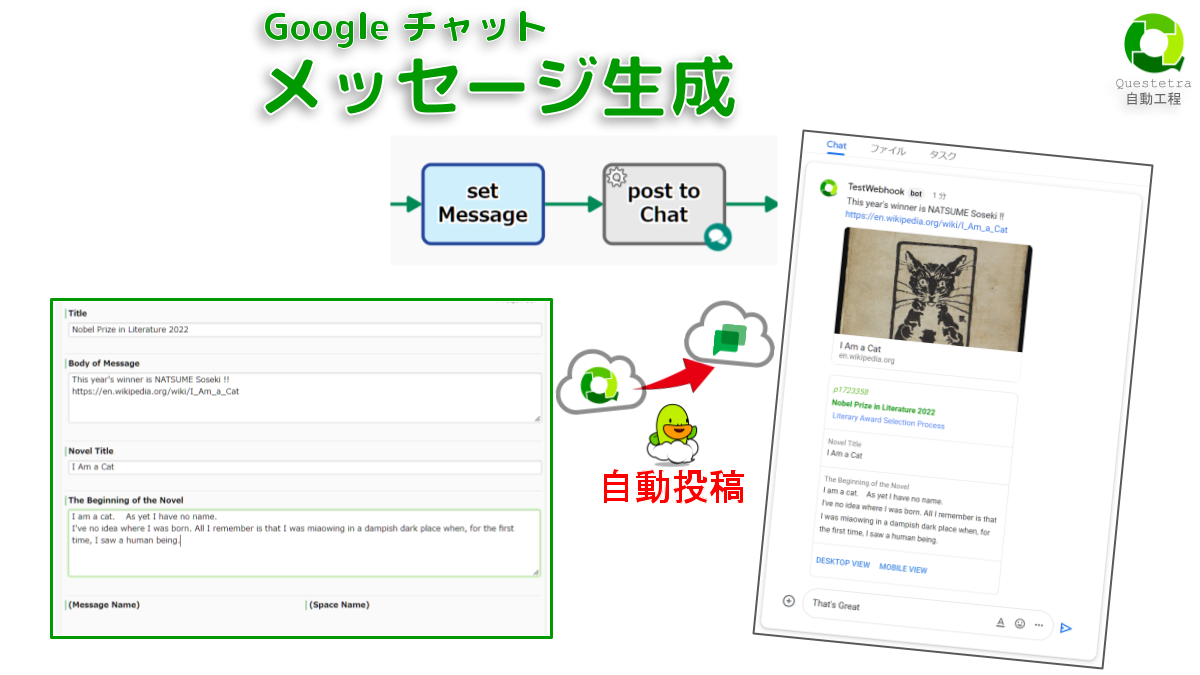
Google Chat #スペース: メッセージ生成
Googleチャットの「スペース」にメッ…
-
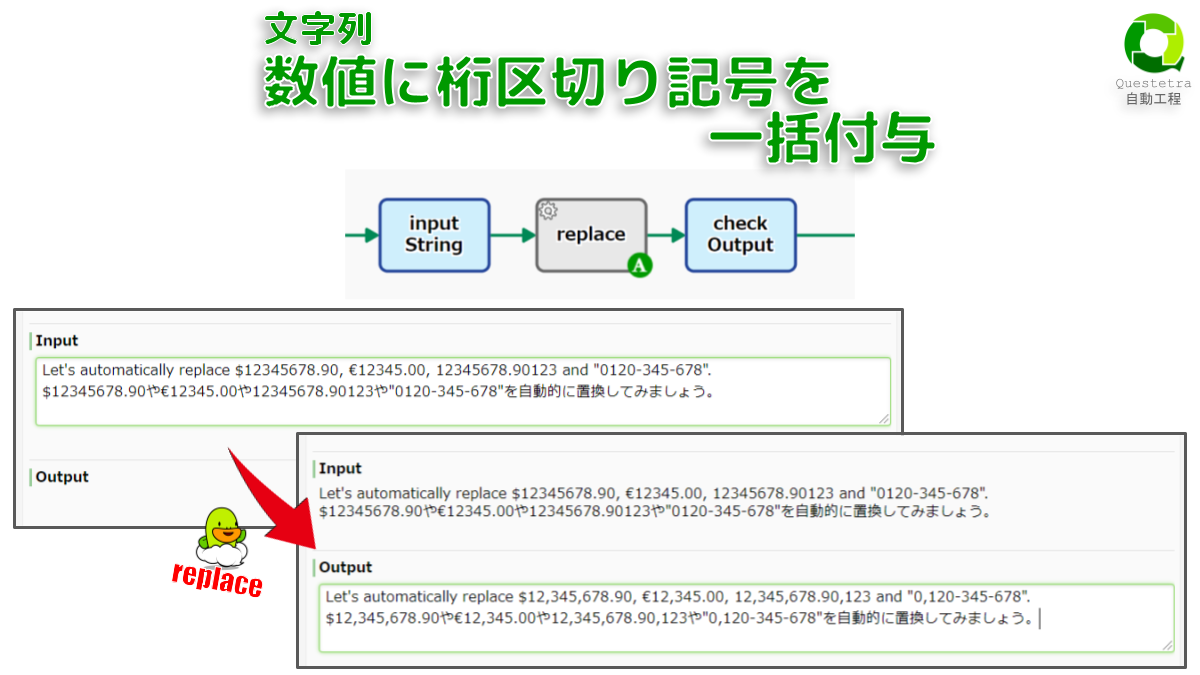
文字列, 数値に桁区切り記号を一括付与
テキスト中の4桁以上数値(数字4連続以上…
-

単一行文字列, 複数行文字列のN行目をセット
複数行文字列の任意の1行を抽出し、単一行…
-

単一行文字列, 複数行文字列からランダムに抽出した1行をセット
複数行文字列の中から1行をランダムに抽出…
-

単一行文字列, 複数行文字列から順繰りに1行をセット
複数行文字列の中から1行を順繰り(ラウン…
-
コンバータ, 複数行文字列 to 単一行CSV文字列
複数行文字列をCSV文字列に変換します。…
-

TSV 文字列, 数値列合計
数値列の値を単純合計します。数値フィール…
-

複数行文字列, テキスト検索
任意の検索テキストで複数行の文字列を検索…
-

選択型データ項目, 自動代入(el-enabled)
任意の文字列と一致する選択肢IDの選択肢…