// GraalJS Script (engine type: 2)
//////// START "main()" /////////////////////////////////////////////////////////////////
main();
function main(){
//// == Config Retrieving / 工程コンフィグの参照 ==
const strInputTsv = configs.get( "StrConfA1" ); /// REQUIRED ///////////////
if( strInputTsv === "" ){
throw new Error( "\n AutomatedTask ConfigError:" +
" Config {A1: TSV} is empty \n" );
}
const arrInputTsv = strInputTsv.split("\n");
let numColMaxWidth = 0;
for( let i = 0; i < arrInputTsv.length; i++ ){
let arrCells = arrInputTsv[i].split("\t");
if( numColMaxWidth < arrCells.length ){ numColMaxWidth = arrCells.length; }
}
engine.log( " AutomatedTask TsvDataCheck: " +
numColMaxWidth + "w " + arrInputTsv.length + "h" );
let strColIds = configs.get( "StrConfB1" ); // NotRequired /////////////
if( strColIds === "" ){
for( let i = 0; i < numColMaxWidth; i++ ){
strColIds += i + "";
if( i !== numColMaxWidth - 1 ){
strColIds += ",";
}
}
} // strColIds: "0,1,2,3,,"
const regCsv = /^[-?0-9][-?0-9,]*[0-9]$/; // RegExp
if( ! regCsv.test( strColIds ) ){
throw new Error( "\n AutomatedTask ConfigError:" +
" Config {B1: ColumnOrder} allows only numbers and commas \n" );
}
const strPocketOutputTsv = configs.getObject( "SelectConfC1" ); // NotRequired ///////
const strPid = processInstance.getProcessInstanceId() + "";
const filesPocketUtf8tsv = configs.getObject( "SelectConfD1" ); // NotRequired ///////
let strSaveasUtf8tsv = configs.get ( "StrConfD2" ); // NotRequired ///////
if( strSaveasUtf8tsv === "" ){
strSaveasUtf8tsv = strPid + "-urf8.tsv";
}
const filesPocketUtf16letsv = configs.getObject( "SelectConfE1" ); // NotRequired ///////
let strSaveasUtf16letsv = configs.get ( "StrConfE2" ); // NotRequired ///////
if( strSaveasUtf16letsv === "" ){
strSaveasUtf16letsv = strPid + "-urf16.csv";
}
const filesPocketUtf8csv = configs.getObject( "SelectConfF1" ); // NotRequired ///////
let strSaveasUtf8csv = configs.get ( "StrConfF2" ); // NotRequired ///////
if( strSaveasUtf8csv === "" ){
strSaveasUtf8csv = strPid + "-urf8.csv";
}
const filesPocketPutf8csv = configs.getObject( "SelectConfG1" ); // NotRequired ///////
let strSaveasPutf8csv = configs.get ( "StrConfG2" ); // NotRequired ///////
if( strSaveasPutf8csv === "" ){
strSaveasPutf8csv = strPid + "-purf8.csv";
}
const filesPocketPsjiscsv = configs.getObject( "SelectConfH1" ); // NotRequired ///////
let strSaveasPsjiscsv = configs.get ( "StrConfH2" ); // NotRequired ///////
if( strSaveasPsjiscsv === "" ){
strSaveasPsjiscsv = strPid + "-psjis.csv";
}
//// == Data Retrieving / ワークフローデータの参照 ==
// (Nothing. Retrieved via Expression Language in Config Retrieving)
//// == Calculating / 演算 ==
let arrColIds = strColIds.split(",");
let strOutputTsv = "";
for( let i = 0; i < arrInputTsv.length; i++ ){
if( arrInputTsv[i] === "" ){ continue; } // Skip blank lines
let arrInputCells = arrInputTsv[i].split("\t");
for( let j = 0; j < arrColIds.length; j++ ){
let numCelId = parseInt( arrColIds[j] );
if( 0 <= numCelId && numCelId < arrInputCells.length ){
strOutputTsv += arrInputCells[numCelId];
}else{
strOutputTsv += "";
}
if( j !== arrColIds.length - 1 ){
strOutputTsv += "\t";
}
}
strOutputTsv += "\n";
}
strOutputTsv = strOutputTsv.slice( 0, -1 ); // delete last "\n"
let strOutputTsvEscaped = ""; // Escaped with another double quote, Enclosed in double quotes
for( let i = 0; i < arrInputTsv.length; i++ ){
if( arrInputTsv[i] === "" ){ continue; } // Skip blank lines
let arrInputCells = arrInputTsv[i].split("\t");
for( let j = 0; j < arrColIds.length; j++ ){
let numCelId = parseInt( arrColIds[j] );
if( 0 <= numCelId && numCelId < arrInputCells.length ){
strOutputTsvEscaped += '"' + // (RFC 4180 2-5)
arrInputCells[numCelId].replace( /"/g, '""' ) + // (RFC 4180 2-7)
'"';
}else{
strOutputTsvEscaped += '""';
}
if( j !== arrColIds.length - 1 ){
strOutputTsvEscaped += "\t";
}
}
strOutputTsvEscaped += "\n";
}
strOutputTsvEscaped = strOutputTsvEscaped.slice( 0, -1 ); // delete last "\n"
//// == Data Updating / ワークフローデータへの代入 ==
if( strPocketOutputTsv !== null ){ // STRING
engine.setData( strPocketOutputTsv, strOutputTsv );
}
if( filesPocketUtf8tsv !== null ){ // FILE
let filesAttachedUtf8tsv = engine.findData( filesPocketUtf8tsv ); // java.util.ArrayList
if( filesAttachedUtf8tsv === null ) {
engine.log( " AutomatedTask FilesArray {Utf8tsv}: (empty)" );
filesAttachedUtf8tsv = new java.util.ArrayList();
}else{
engine.log( " AutomatedTask FilesArray {Utf8tsv}: " +
filesAttachedUtf8tsv.size() + " files" );
}
filesAttachedUtf8tsv.add(
new com.questetra.bpms.core.event.scripttask.NewQfile(
strSaveasUtf8tsv,
"text/tab-separated-values; charset=UTF-8",
strOutputTsv
)
);
engine.setData( filesPocketUtf8tsv, filesAttachedUtf8tsv );
}
if( filesPocketUtf16letsv !== null ){ // FILE
let filesAttachedUtf16letsv = engine.findData( filesPocketUtf16letsv ); // java.util.ArrayList
if( filesAttachedUtf16letsv === null ) {
engine.log( " AutomatedTask FilesArray {Utf16letsv}: (empty)" );
filesAttachedUtf16letsv = new java.util.ArrayList();
}else{
engine.log( " AutomatedTask FilesArray {Utf16letsv}: " +
filesAttachedUtf16letsv.size() + " files" );
}
filesAttachedUtf16letsv.add(
new com.questetra.bpms.core.event.scripttask.NewQfile(
strSaveasUtf16letsv,
"text/tab-separated-values; charset=x-UTF-16LE-BOM",
strOutputTsv
)
);
engine.setData( filesPocketUtf16letsv, filesAttachedUtf16letsv );
}
if( filesPocketUtf8csv !== null ){ // FILE
let filesAttachedUtf8csv = engine.findData( filesPocketUtf8csv ); // java.util.ArrayList
if( filesAttachedUtf8csv === null ) {
engine.log( " AutomatedTask FilesArray {Utf8csv}: (empty)" );
filesAttachedUtf8csv = new java.util.ArrayList();
}else{
engine.log( " AutomatedTask FilesArray {Utf8csv}: " +
filesAttachedUtf8csv.size() + " files" );
}
filesAttachedUtf8csv.add(
new com.questetra.bpms.core.event.scripttask.NewQfile(
strSaveasUtf8csv,
"text/csv; charset=UTF-8",
strOutputTsvEscaped.replace( /\t/g, "," )
)
);
engine.setData( filesPocketUtf8csv, filesAttachedUtf8csv );
}
if( filesPocketPutf8csv !== null ){ // FILE
let filesAttachedPutf8csv = engine.findData( filesPocketPutf8csv ); // java.util.ArrayList
if( filesAttachedPutf8csv === null ) {
engine.log( " AutomatedTask FilesArray {Putf8csv}: (empty)" );
filesAttachedPutf8csv = new java.util.ArrayList();
}else{
engine.log( " AutomatedTask FilesArray {Putf8csv}: " +
filesAttachedPutf8csv.size() + " files" );
}
filesAttachedPutf8csv.add(
new com.questetra.bpms.core.event.scripttask.NewQfile(
strSaveasPutf8csv,
"text/tab-separated-values; charset=UTF-8",
strOutputTsv.replace( /,/g, "" ).replace( /\t/g, "," )
)
);
engine.setData( filesPocketPutf8csv, filesAttachedPutf8csv );
}
if( filesPocketPsjiscsv !== null ){ // FILE
let filesAttachedPsjiscsv = engine.findData( filesPocketPsjiscsv ); // java.util.ArrayList
if( filesAttachedPsjiscsv === null ) {
engine.log( " AutomatedTask FilesArray {Psjiscsv}: (empty)" );
filesAttachedPsjiscsv = new java.util.ArrayList();
}else{
engine.log( " AutomatedTask FilesArray {Psjiscsv}: " +
filesAttachedPsjiscsv.size() + " files" );
}
filesAttachedPsjiscsv.add(
new com.questetra.bpms.core.event.scripttask.NewQfile(
strSaveasPsjiscsv,
"text/tab-separated-values; charset=Shift_JIS",
strOutputTsv.replace( /,/g, "" ).replace( /\t/g, "," )
)
);
engine.setData( filesPocketPsjiscsv, filesAttachedPsjiscsv );
}
} //////// END "main()" /////////////////////////////////////////////////////////////////
/*
Notes:
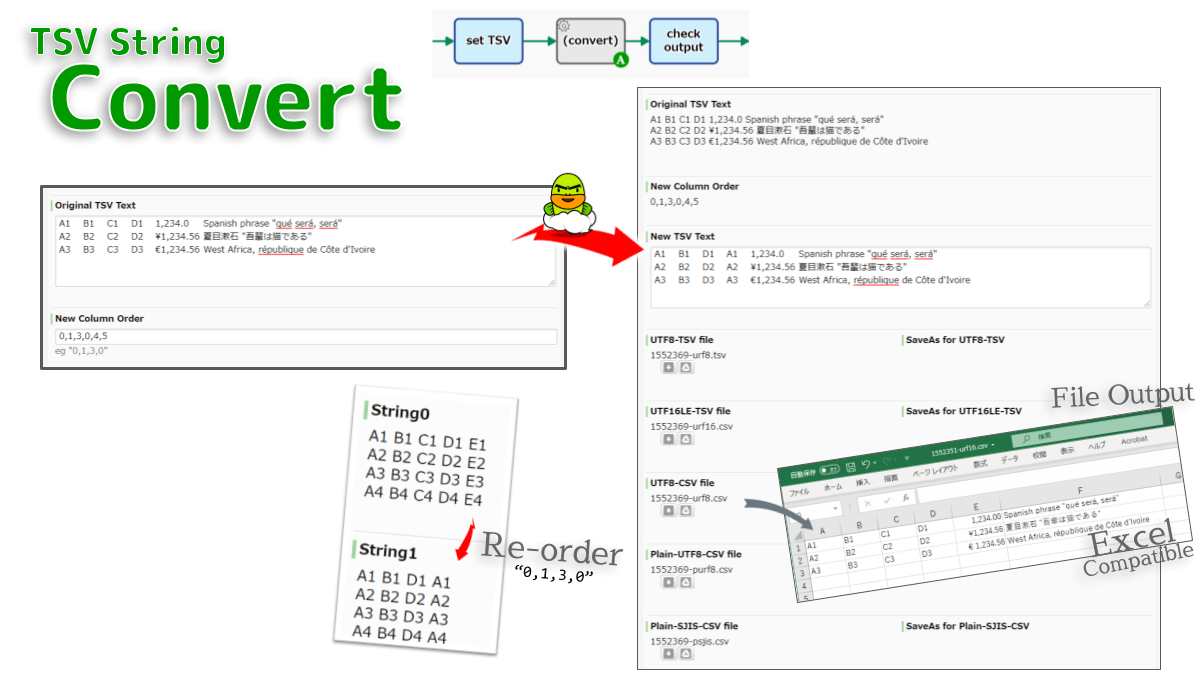
- Used when incorporating "the step in which TSV text is automatically edited" into the workflow.
- When the process reaches this automated task, the TSV stored in string data is automatically processed.
- Column reordering
- File output (`text/tab-separated-values`,`text/csv`)
- The output order is specified by enumerating the column IDs of the input TSV (lile "0" and "3").
- If an inaccessible ID (such as "999" or "-1") is specified, an empty string (length 0) will be inserted.
- The number of columns can be added. (eg; combining TSVs, adding header line, etc.)
- If not specified, all columns will be output as they were originally.
- If the number of cells differs depending on the row, the output will be adjusted to the maximum number.
- Blank lines (line breaks only) in the input TSV text are ignored.
- If SaveAs is not set, the file name will be `{pid}-urf8.csv` etc.
APPENDIX:
- The input TSV is parsed as the simplest tab-delimited text. (`UTF-8` encoding)
- Double quotes are interpreted as cell data just like any other character.
- It is not possible to have "tab" or "line feed" data in the cell data (in the field).
- LF is assumed as the line feed code.
- Even if it is CRLF or CR, it can be processed normally.
- https://en.wikipedia.org/wiki/Tab-separated_values
- If you want to combine two TSV data as an input TSV, set Config in two lines.
- `#{#q_tsv_string_data_1}`
- `#{#q_tsv_string_data_2}`
- If you want to add header line as input TSV, add the header line to the first line of Config.
- `header-cel-A` TAB `header-cel-B` TAB `header-cel-C`
- `#{#q_tsv_string_data}`
- The number of cells in the output TSV is the same for all rows. (Fixed Column Width)
- The line feed code is not added to the last line.
- `UTF-8`
- Compactly encodes more than 1 million Unicode characters in the world with 1 to 4 bytes.
- It became the most common character code in 2008 and is used in 97% of web pages as of 2021.
- UTF-8 is superset of US-ASCII (single-byte characters). (upward compatible)
- That is, ASCII files are also UTF-8 files. (US-ASCII is a subset of UTF-8)
- Similarly, ASCII files are also Shift_JIS files.
- `UTF-16`
- Encodes over 1 million Unicode characters in the world with 2-4 bytes.
- If there are many Asian characters such as Japanese and Chinese, encode them compactly.
- File output can be output in several formats.
- UTF8 TSV **Recommended**
- MIME type: `text/tab-separated-values; charset=UTF-8`
- Encoding: `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak: `LF`
- Delimiter: `TAB`
- https://ja.wikipedia.org/wiki/Tab-Separated_Values
- It is very often used for File-based Integration.
- As a file for Windows software, characters may be garbled (misidentified by Shift_JIS etc.).
- The simplest and most versatile tab-delimited text.
- Cell values (field values) are not enclosed in quotation marks such as double quotes.
- Double quotes in cells (in fields) are retained as double quotes.
- UTF16LE TSV (Excel compatible CSV) **Recommended**
- MIME type: `text/csv; charset=x-UTF-16LE-BOM`
- Encoding: `x-UTF-16LE-BOM`
- Linebreak: `LF`
- Delimiter: `TAB`
- https://en.wikipedia.org/wiki/Comma-separated_values
- In many cases, it is called a CSV file and the extension is `.csv`, but in reality it is tab-delimited.
- The file will be several bytes larger than `charset=UTF-16` and` charset=UTF-16BE`.
- Very often used as a file for Excel import. (OS does not matter / Risk of garbled characters is almost avoided)
- Often used as a file for Windows software.
- The file for File-based Integration may cause a problem.
- It cannot be used as a file for legacy software (for example, software that assumes US-ASCII).
- The simplest and most versatile tab-delimited text.
- Cell values(field values) are not enclosed in quotation marks such as double quotes.
- Double quote characters in cells (in fields) are retained as double quote characters.
- UTF8 CSV
- MIME type: `text/csv; charset=UTF-8`
- Encoding: `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak: `LF`
- Delimiter: `,` (COMMA)
- It is very often used for File-based Integration.
- As a file for Windows software, characters may be garbled (misidentified by Shift_JIS etc.).
- A comma-separated format output by many software.
- All cell values (field values) are enclosed in double quotes. (RFC 4180 2-5)
- Double quote characters in cells are escaped preceded by double quote characters. (RFC 4180 2-7)
- Plain UTF8 CSV (Extra Commas Removed)
- MIME type: `text/csv; charset=UTF-8`
- Encoding: `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak: `LF`
- Delimiter: `,` (COMMA)
- Often used for File-based Integration
- As a file for Windows software, characters may be garbled (misidentified by Shift_JIS etc.).
- Comma separated format with extra comma characters removed.
- All comma characters (digit separators, etc.) in the cell (in the field) are removed.
- It is often used as a management file for accounting data and aggregated data.
- Cell values(field values) are not enclosed in quotation marks such as double quotes.
- If there are double quote characters in the cell (in the field), they are all removed. (RFC 4180 2-5)
- Plain SJIS CSV (Extra Commas Removed)
- MIME type: `text/csv; charset=Shift_JIS`
- Encoding: `Shift_JIS`
- Linebreak: `LF`
- Delimiter: `,` (COMMA)
- Often used for File-based Integration
- It is very often used as a file for importing Excel in Japan. (Almost avoiding the risk of garbled characters)
- It is very often used as a file for Windows software in Japan. (Almost avoiding the risk of garbled characters)
- Comma separated format with extra comma characters removed.
- All comma characters (digit separators, etc.) in the cell (in the field) are removed.
- It is often used as a management file for aggregated data, accounting data, transfer data, etc. in Japan.
- Cell values (field values) are not enclosed in quotation marks such as double quotes.
- If there are double quote characters in the cell (in the field), they are all removed. (RFC 4180 2-5)
- If you want to convert to another encoding, consider the downstream arrangement of "Text file, encoding conversion".
- `charset=UTF-16` (Unicode [characters around the world])
- `charset=UTF-16BE` (Unicode [characters around the world])
- `charset=UTF-16LE` (Unicode [characters around the world])
- `charset=UTF-32` (Unicode [characters around the world])
- `charset=x-UTF-32LE-BOM` (Unicode [characters around the world])
- `charset=ISO-8859-1` (Western language characters)
- `charset=Shift_JIS` (Japanese characters)
- `charset=Big5` (Traditional Chinese characters)
- `charset=GB2312` (Simplified Chinese EUC characters)
- `charset=GBK` (Simplified Chinese GB characters)
- `charset=KOI8-R` (Russian)
- In addition, "UTF8B (UTF-8 with BOM)" cannot be output. (File for Windows / pray for its eradication)
- https://docs.oracle.com/javase/9/intl/supported-encodings.htm
Notes-ja:
- ワークフロー内に「TSVテキストが自動的に加工される工程」を組み込む際に利用します。
- 案件が自動処理工程に到達した際、文字列型データに保存されたTSVが自動的に加工されます。
- カラムの並べ替え、取捨選択
- ファイル化 ( `text/tab-separated-values`, `text/csv` )
- 出力順は入力TSVの列ID("0" や "3" など)を列挙して指定します。
- アクセスできない列ID("999" や "-1" など)が指定された場合、空文字(長さ0の文字列)が挿入されます。
- カラム数の追加が可能です。 (TSV 同士の結合、ヘッダ行の追加、などの用途)
- 指定がない場合、全ての列(カラム)をオリジナル通りに出力します。
- 行によってセルの数が異なる場合、最大数にあわせて出力されます。
- TSVテキスト(入力)内の空行(改行のみの行)は無視されます。
- 別名保存が未設定の場合、`{pid}-urf8.csv` といったファイル名になります。
APPENDIX-ja:
- 入力TSVは「もっともシンプルなタブ区切りテキスト」として解析されます。 (`UTF-8` encoding)
- ダブルクオート(二重引用符)による囲みは、他の文字と同じようにセルデータとして解釈されます。
- セルデータ内(フィールド内)に「タブ」や「改行」のデータを持たせることはできません。
- 改行コードはLFが想定されます。
- 仮にCRLFやCRであっても、正常に処理可能です。
- https://en.wikipedia.org/wiki/Tab-separated_values
- もし「2つのTSVデータを結合」して入力TSVとしたい場合、Config を2行に分けて設定します。
- `#{#q_tsv_string_data_1}`
- `#{#q_tsv_string_data_2}`
- もし「ヘッダ行を追加」した上で入力TSVにしたい場合、Config の1行目にヘッダ行を追記します。
- `header-cel-A` TAB `header-cel-B` TAB `header-cel-C`
- `#{#q_tsv_string_data}`
- 出力TSVにおけるセルの数は、全ての行で同じ数となります。(Fixed Column Width)
- なお、最終行に改行コードは付与されません。
- `UTF-8`
- 世界100万種以上のUnicode文字を、1~4バイトでコンパクトにエンコードします。
- 2008年に最も一般的な文字コードとなり、2021年時点で97%のウェブページで利用されています。
- UTF-8 は US-ASCII(1バイト文字)の上位互換です。(US-ASCII は UTF-8 のサブセットです)
- すなわち ASCII ファイルは UTF-8 ファイルでもあります。
- 同様に ASCII ファイルは Shift_JIS ファイルでもあります。
- `UTF-16`
- 世界100万種以上のUnicode文字を、2~4バイトでエンコードします。
- 日本語や中国語などのアジア文字が多い場合は、コンパクトにエンコードします。
- ファイル出力は、幾つかの書式で出力可能です。
- UTF8 TSV **【推奨】**
- MIME type: `text/tab-separated-values; charset=UTF-8`
- Encoding (符号化方式): `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak (改行コード): `LF`
- Delimiter (区切り記号): `TAB`
- https://ja.wikipedia.org/wiki/Tab-Separated_Values
- システム連携ファイルとして、とてもよく利用されます。
- Windowsソフトウェア用のファイルとしては、文字化けする(Shift_JIS等に誤認される)場合があります。
- もっともシンプルで汎用的なタブ区切りテキストです。
- セル値(フィールド値)がダブルクオート等の引用符で囲まれることはありません。
- セル内(フィールド内)のダブルクオートは、そのままダブルクオートとして保持されます。
- UTF16LE TSV (Excel互換 CSV) **【推奨】**
- MIME type: `text/csv; charset=x-UTF-16LE-BOM`
- Encoding (符号化方式): `x-UTF-16LE-BOM`
- Linebreak (改行コード): `LF`
- Delimiter (区切り記号): `TAB`
- https://en.wikipedia.org/wiki/Comma-separated_values
- 多くの場合CSVファイルと呼ばれ、拡張子も`.csv`とされますが、実態としてはタブ区切りです。
- `charset=UTF-16` や `charset=UTF-16BE` より、数バイト大きなファイルになります。
- Excelインポート用ファイルとして、とてもよく利用されます。(OS不問/文字化けリスクほぼ回避)
- Windowsソフトウェア用のファイルとして、よく利用されます。
- システム連携用ファイルとしては、不具合の原因となる場合があります。
- レガシーソフト(たとえば US-ASCII を前提とするソフトウェア)用のファイルとしては、利用できません。
- もっともシンプルで汎用的なタブ区切りテキストです。
- セル値(フィールド値)がダブルクオート等の引用符で囲まれることはありません。
- セル内(フィールド内)のダブルクオート文字は、そのままダブルクオート文字として保持されます。
- UTF8 CSV
- MIME type: `text/csv; charset=UTF-8`
- Encoding (符号化方式): `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak (改行コード): `LF`
- Delimiter (区切り記号): `,` (COMMA)
- システム連携ファイルとして、とてもよく利用されます。
- Windowsソフトウェア用のファイルとしては、文字化けする(Shift_JIS等に誤認される)場合があります。
- 多くのソフトウェアが出力する汎用的なカンマ区切りフォーマットです。
- 全てのセル値(フィールド値)はダブルクオート引用符で囲まれます。(RFC 4180 2-5)
- セル内のダブルクオート文字は、ダブルクオート文字を前置してエスケープされます。(RFC 4180 2-7)
- Plain UTF8 CSV (Extra Commas Removed)
- MIME type: `text/csv; charset=UTF-8`
- Encoding (符号化方式): `UTF-8` no BOM (utf8n, UTF-8N)
- Linebreak (改行コード): `LF`
- Delimiter (区切り記号): `,` (COMMA)
- システム連携ファイルとして、しばしば利用されます。
- Windowsソフトウェア用のファイルとしては、文字化けする(Shift_JIS等に誤認される)場合があります。
- 余分なカンマ文字が除去されたカンマ区切りフォーマットです。
- セル内(フィールド内)のカンマ文字(桁区切り文字等)が、全て除去されます。
- 会計データや集計データなどの管理ファイルとして、よく利用されます。
- セル値(フィールド値)がダブルクオート等の引用符で囲まれることはありません。
- セル内(フィールド内)にダブルクオート文字があった場合、全て除去されます。(RFC 4180 2-5)
- Plain SJIS CSV (Extra Commas Removed)
- MIME type: `text/csv; charset=Shift_JIS`
- Encoding (符号化方式): `Shift_JIS`
- Linebreak (改行コード): `LF`
- Delimiter (区切り記号): `,` (COMMA)
- システム連携ファイルとして、しばしば利用されます。
- 日本におけるExcelインポート用ファイルとして、とてもよく利用されます。(文字化けリスクほぼ回避)
- 日本におけるWindowsソフトウェア用のファイルとして、とてもよく利用されます。(文字化けリスクほぼ回避)
- 余分なカンマ文字が除去されたカンマ区切りフォーマットです。
- セル内(フィールド内)のカンマ文字(桁区切り文字等)が、全て除去されます。
- 日本における集計データ・会計データ・振込データなどの管理ファイルとして、よく利用されます。
- セル値(フィールド値)がダブルクオート等の引用符で囲まれることはありません。
- セル内(フィールド内)にダブルクオート文字があった場合、全て除去されます。(RFC 4180 2-5)
- 他のエンコーディングに変換したい場合は、『テキストファイル, エンコーディングの変換』の下流配置を検討します。
- `charset=UTF-16` (Unicode[世界中の文字])
- `charset=UTF-16BE` (Unicode[世界中の文字])
- `charset=UTF-16LE` (Unicode[世界中の文字])
- `charset=UTF-32` (Unicode[世界中の文字])
- `charset=x-UTF-32LE-BOM` (Unicode[世界中の文字])
- `charset=ISO-8859-1` (ヨーロッパ言語の文字)
- `charset=Shift_JIS` (日本語の文字)
- `charset=Big5` (繁体中国語の文字)
- `charset=GB2312` (簡体中国語EUC文字)
- `charset=GBK` (簡体中国語GBの文字)
- `charset=KOI8-R` (ロシア語)
- なお "UTF8B (BOM付 UTF-8)" は出力できません。(Windows用ファイル/その撲滅を祈念)
- https://docs.oracle.com/javase/9/intl/supported-encodings.htm
- https://docs.oracle.com/javase/jp/9/intl/supported-encodings.htm
*/